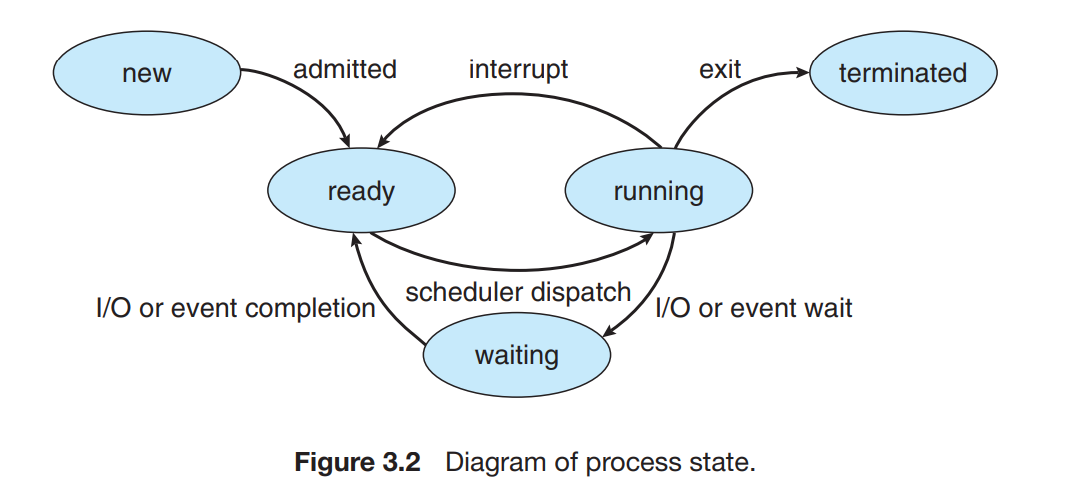
Operating System
OPERATING SYSTEM
- Moores Law: Every decade the number of digital devices will double themselves.
- Kernel is the core component of the OS system and it is used for system calls and other utility works while OS is generally used for user interface.
- Bootstrap Program : The program required by the Computer to start running. It is stored inside ROM or EEPROM(Electrically Erasable Programmable Read-Only Memory) as firmware.
- system daemons are the processes loaded outside the kernel and then loaded during the boot time into ROM. On UNIX it is (init).
- system calls are actually the interrupts called by a software.
VonNeumann Arch:
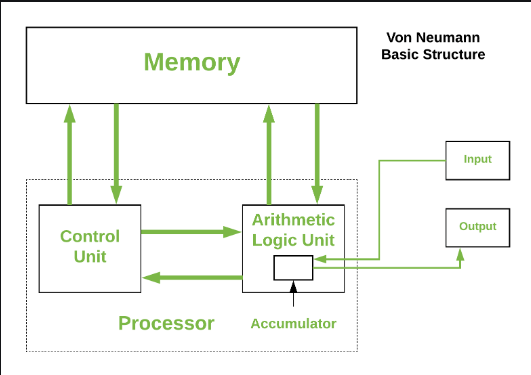
- Buses
- Data bus: carries data among the memory units
- Address Bus: carries address of the data
- Control Bus: carries control commands of the CPU and hardware like interrupt signals.
- Von Neumann Bottleneck: It is the sequential processing of the instructions one at a time.
Harvard Arch:
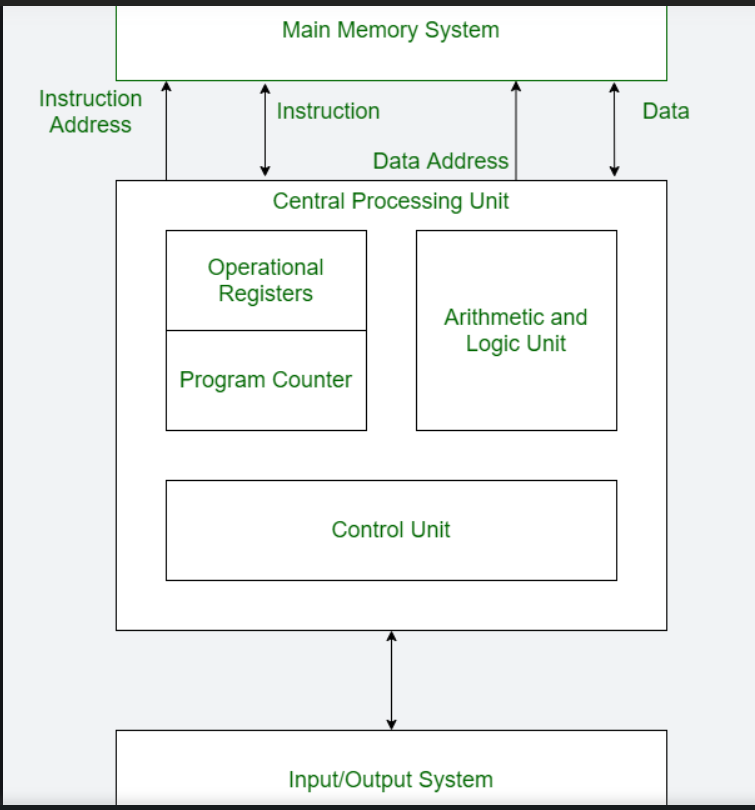
- The basic diff is that it has diff buses for transferring instrns and data unlike vonNeumann architecture that cannot do both simultaneously.
- The instrns and the simple data are stored in diff sections of memory.
1
2
3
4
5
6
7
8
9
SIC
Simplified Instructional Computer: hypothetical computer
Register size is 3 bytes.
I. A(Accumulator-0): It is used for mathematical operations.
II. X(Index Register-1): It is used for addressing.
III. L(Linkage Register-2): It stores the return address of the instruction in case of subroutines.
IV. PC(Program Counter-8): It holds the address of the next instruction to be executed.
V. SW(Status Word-9): It contains a variety of information
- Pipelining in 8086 processor:
- It helps in execution of multiple instrns simulataneously (does fetch and exeute simultaneously).
- It leads to one instrn loss in case of branched instrns.
I/O Devices
- DMA(Direct Memory Acess) It lets the devices acess the data directly instead of processing it throught the processor.
- Single ended: read and write from single address
- Dual ended: read/write from 2 addresses
- Arbitrated ended: read/write to multi addresses.
- Interleaved ended: read from one and write to another.
Graceful Degradation
- Graceful degradation refers to the system’s ability to maintain essential functionality and continue operating in a degraded or reduced-performance state when faced with failures, errors, or resource limitations.
How to overcome it ??
- Use fault tolerance methods like disk isolation or using non-corrupted memory areas.
Assymetric multiprocessing
- All the work is assigned by the boss processor to the worker processors.
- All do the specified work only
Symmetric multiprocessing
- All work is done by all worker processors.
No boss worker relation.
- Darwin, the core kernel component of Mac OS X
1
2
3
4
5
6
7
8
9
10
11
Three main functions of OS:
1. Resource management:
- CPU scheduling
- Memory management
- File System
2. User Interface
- GUI
- I/O devices
3. Process Management
- Process schedulling
- Process communication and synchronization of different processes.
1
The OS is allowed to waste resources in the case it has to do fault tolerance or it has ample amount of resources to increase the render speed of the OS.
1
2
abort() : abnormal halt
end(): normal halt
System calls

- Functions or syscalls on Windows and Linux systems

- Locking of Data: This is to share the data between two programs and ensure that no other program can acess them in between. {acquire_lock() and release_lock()}
- Single Tasking system: Just like MS-DOS, the system gives all the memory to the process and overwrites its memory portion.When the process terminates, the memory is retrieved by the command interpreter.
- Multi Tasking System: They assign small portion of memory to the process and the command interpreter can work simultaneously and also can spawn other different programs.
- Process ID: They are used to identify the details of a riunning process. {get hostid() and get processid()}
OS design and implementation
Real time OS:
A real-time operating system (RTOS) is an operating system specifically designed to handle real-time applications that have timing constraints and require precise and deterministic responses to events
Distributed OS
A distributed operating system (DOS) is an operating system that runs on multiple interconnected computers, allowing them to work together as a unified computing environment.
Multiuser OS
A multiuser operating system is designed to allow multiple users to access and use a computer system concurrently
How does OS starts?


Process Management
Contents:
- data section: It contains all the global variables.
- stack section: It contains all the coded functions and local variables and parameters.
- text section: It has the current program counter.
- heap section: It has all the dynamically allocated data.
1
In Java programs, as we type 'Java Program' to run the class "Program" . It will spawn a JVM (Java Virtual MAchine) that will run the java code inside it and then execute all the instructions it finds through its program counter.
- PCB(Process Control Block)
- It is the representation of a process specific details.
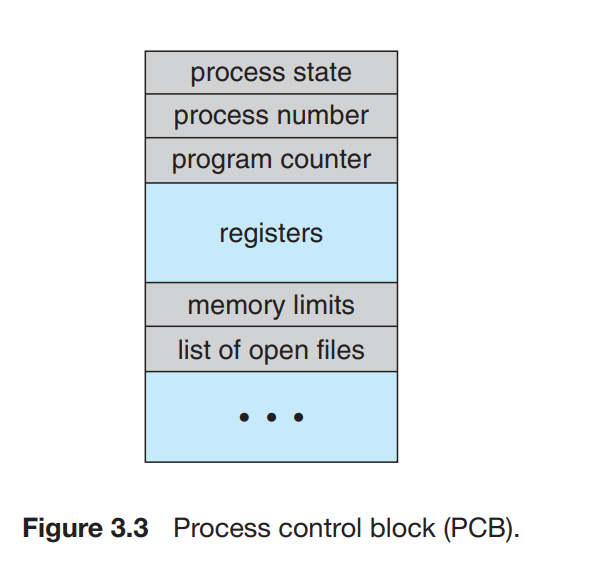
Process Scheduling
- It decides which process to execute using the processor in the CPU to make sure that the priority processes are dealt and executed first.
It distributes the processes among the CPU processors to execute all of them one by one.
- Scheduling Queues
- Job queue: As a process enters the system it goes inside the job queue.
Ready Queue: It has the processes waiting to be executed.
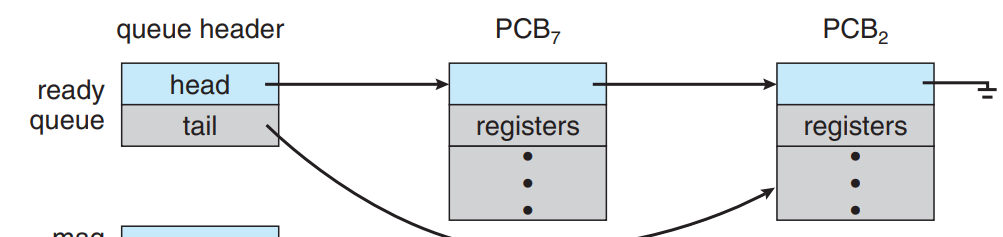
It basically acts as a linked list whose head points to the next control block.
- Device Queue: The processes that are waiting for an I/O device to execute some process are stored inside this queue.
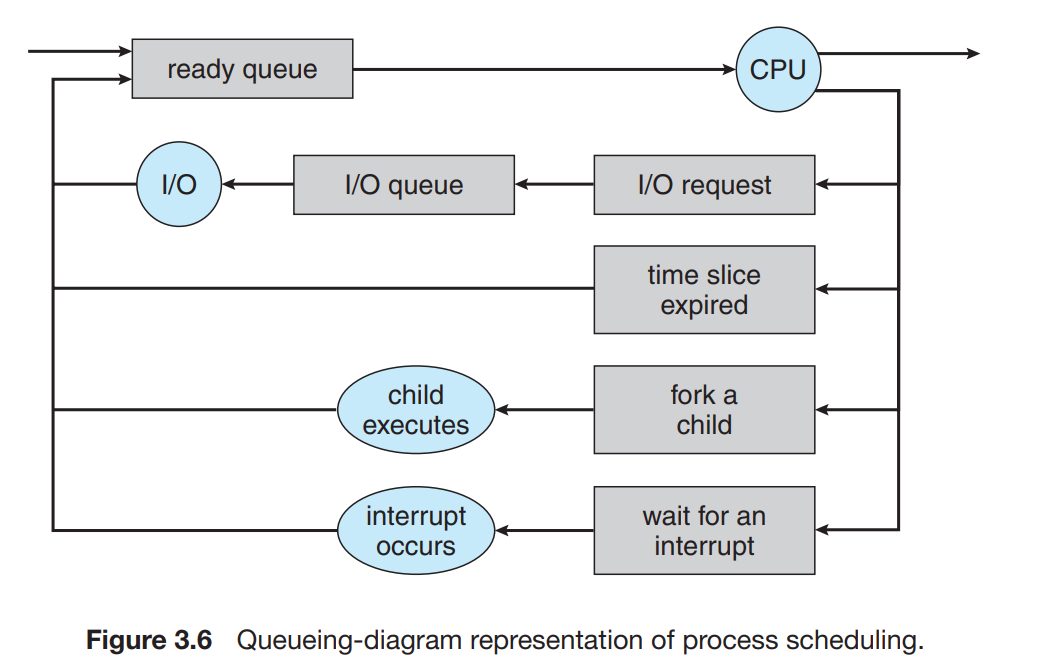
- Scheduler
Long-Term Scheduler/Job scheduler: It chooses which program to get inside the job queue. It takles a long period of time as schedulling more than one program may take a long period of time. But it is absent in many general OS systems to increase speed while decreasing the performance of the programs.
Short-term Scheduler/CPU scheudler: It chooses which process to turn to the CPU from the job queue. It must have a high frequency of scheduling the programs to make sure that the CPU gets the programs to be executed in short-period duration.
Mid-term Scheduler: It helps in swapping of the programs that can be executed afterwards using the swapping pointer. Swapping is a process of storing the process outside the queue and getting it back to the queue after a short period of time so that the CPU can execute other programs easily. It swaps the processes with generally inactive sessions or sleeping processes and other waste processes between RAM and Disk.
Process Termination
1
2
3
4
The child process can exit if:
- child process has used more resources than it was assgined.
- parent process is exiting.
- the task asigned to child process is no longer required.
Many of the systems donot allow any child process ti function if the parent process is not functioning thus it is called cascading termination.
Most parent processes come to know about the state of the child process by the wait() syscall.
Zombie Process
They are the child processes that have terminated but still have not been called wait() syscall by their parent processes.
Orphans
They are the child processes whose parent processes have terminated but they are still functioning. In UNIX systems, this situation is dealt by making the init process as the parent of these type of child processes.
Calling wait() syscall is essential for the parent processes to enter the child process into the Process Table so that it can be released and terminated.
Interprocess Communication
- Independent Process: not affected by other processes
Cooperating Process: affected by other processes
Shared memory Systems
- They create a shared memory space inside the disk memory and all the processes that require to share their memory have to have this space inside their own memory space.
- The form of data does’nt depend upon the OS but on the processes themselves. The data is to be written inside the shared memory region and then read by the other processes.
- Buffers: To have buffers inside the shared memory region for sharing resources
- Unbounded buffer: It has no limit of size and the producer as well as the consumer process not have to wait to fetch and write data.
- Bounder buffer: The producer cannot write if the buffer is full and the consumer cannot fetch if the buffer is empty.
- Message passing
- The processes share no memory as common but transfer data as required by them.
- Direct Communicaiton:
- symmetry addressing: Both the sender and the receiver names the other process in order to send or receive data.
- assymmetry addressing: Only the sender names the receiver and the receiver need not name the sender.
- Indirect Communication: It involves setting up of a mailbox that can be used to share data.
- The sender first sends the data to the mailbox which is referenced and acessed by the receiver. (POSIX API attaches a pointer to the mailbox entity).
- Only the owner of the mailbox can receive the data from the mailbox.
- Synchronization
- Blocking send. The sending process is blocked until the message is received by the receiving process or by the mailbox.
- Nonblocking send. The sending process sends the message and resumes operation.
- Blocking receive. The receiver blocks until a message is available.
- Nonblocking receive. The receiver retrieves either a valid message or a null.
- Buffering The data is stored inside a temporary queue befire sending it to the receiver.
Zero capacity queue: This queue has zero capacity and thus the data has to be sent and received as soon as possible. The sender must block until the data is recevied by the receiver.
Bounded Capacity: There is a finite limit. The sender must block if the buffer or queue is full.
Unbounded Queue: There is infinite capacity of the queue and thus the sender never has to block in order to send messages.
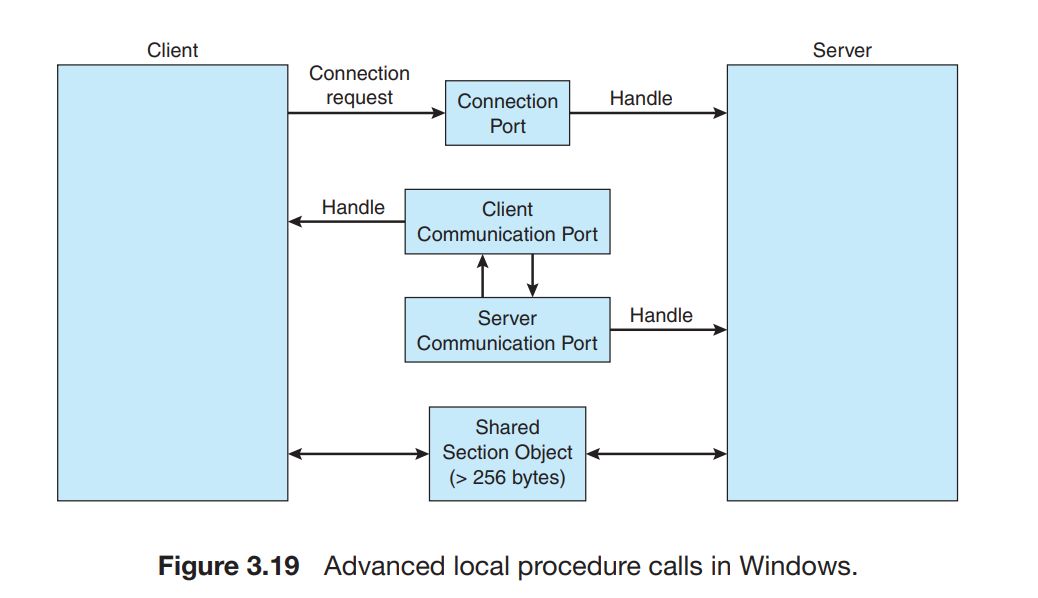
Client-Server comms
- Socket:
- It is the endpoint of the communication.
- Ex: (192.168.5.201:80) represents a socket.
- Port All port number greater than 1024 are considered not well known and thus are used by the temporary servers or clients.
1
The server uses accept() method to establish the connection with the client by accepting the client socket.
1
127.0.0.1 is called the loopback is the IP address at which the client and server is the same local machine and it can communicate with itself.
- Remote Procedure Calls
- Parameter marshalling involves packaging the parameters into a form that can be transmitted over a network.
1 2
Little endian: Least sig bit first Big endian: Most significant bit first
- XDR(eXternal Data Representation)
- The data transmitted by the client or the server is first decrypted to the XDR form and then to the machine code.
- This decryption routine or process is called Unmarshalling and encrypting to XDR by the client is called Marshallling.
- One issue with XDR is that it can fail due to network error:
- For this, we implement the
exactly onceandat most once.- Exactly once: The server makes sure it never receive the same requests using ACK signals from the client. The client keeps on sending the RPC call until and unless ACK call is recognized by the server.
- At most once: The server keeps the record of the timestamps of the requests to make sure it is never received again.
- For this, we implement the
- Parameter marshalling involves packaging the parameters into a form that can be transmitted over a network.
- Pipes They are not bidirectional.
- Anonymous Pipes:
- They are created using
CreatePipefunction. - Data flows either from child process to Parent process or either the other way.
- They are created using
- Named Pipes:
- They are created using
mkfifofunction. - They are bidirectional and more powwerful.
- They can be used to communicate between unrelated processes.
1 2 3 4 5 6 7 8 9
Terminal 1 mkfifo my_pipe cat < my_pipe Terminal 2 echo "Hello, pipe!" > my_pipe
- They are created using
- Half Duplex Communication
- Data can travel in both directions, while it can receive or send but not simulataneously.
Full Duplex Communication
Ordinary Pipes They are one way communication media that have a read-end and a write-end. {Read-end: fd[0] and Write-end: fd[1]}
For UNIX:
1
pipe(int fd[])
- Forking
1 2 3 4 5 6 7 8 9 10 11 12
#include <stdio.h> #include <unistd.h> int main() { /* fork a child process */ fork(); /* fork another child process */ fork(); /* and fork another */ fork(); return 0; }- Here first fork() syscall gives us 2 processes. Then second fork() instead of forking just one process in parent process. It forks() a process on the child process 2 giving us 4 processes. Thus at last we will have 1+2+4+8 = 15 processes.
- Resource Sharing
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18
#include <sys/types.h> #include <stdio.h> #include <unistd.h> int value = 5; int main() { pid t pid; pid = fork(); if (pid == 0) { /* child process */ value += 15; return 0; } else if (pid > 0) { /* parent process */ wait(NULL); printf("PARENT: value = %d",value); /* LINE A */ return 0; } }- The parent process and the child process share the same resources like variables and code space.
- Thus the output will be
PARENT: value=20.
1
.data section: contains all the static and global variables.
1
When a parent process forks a new child process then they both share the ".data", ".text" as well as "heap" sections of the parent process.
- Anonymous Pipes:
Threads
OpenMP
It provides parallel processing that lets different code snippets run in parallel but different regions.
1 2 3 4 5 6 7 8 9 10 11 12
#include <omp.h> #include <stdio.h> int main(int argc, char *argv[]) { /* sequential code */ #pragma omp parallel { printf("I am a parallel region."); } /* sequential code */ return 0; }- This directive creates as many threads
1
#pragma omp parallel
GCD (Grand Central Dispatch)
- Dispatch Queue:
- Serial queue
- It executes one task at a time.
- Tasks are executed in a given order.
- Concurrent Queue
- It can execute multiple tasks simultaneously.
- Serial queue
- It has the thread pool composed of POSIX threads that can be used to execute any task anytime according to the app’s demand.
1 2
If a thread invokes the exec() system call, the program specified in the parameter to exec() will replace the entire process—including all threads.
- Dispatch Queue:
- Signal Handling
Default signal handler:
Every signal has a default signal handler that the kernel runs when handling that signal.
Transferring the signal to a thread:
1
pthread kill(pthread t tid, int signal)
Thread cancellation
It is terminating a thread before even full execution of the thread.
Asynchronous cancellation.
One thread immediately terminates the target thread.
Deferred cancellation.
The target thread periodically checks whether it should terminate and then cancels the thread systematically.
It is the default cancellation technique that only cancels the thread once the thread activity is finished.
- Thread Local Storage
- This is the thread’s own copy of data.
- It is similar to static data or can be understood as local variables.
- Scheduler Activations
- It resolves the issue of the threads communication between them and the user library.
- It is done by making a data-structure “Lightweight Process”.
- The thread library is like a virtual processor on which the user can schedule his threads.
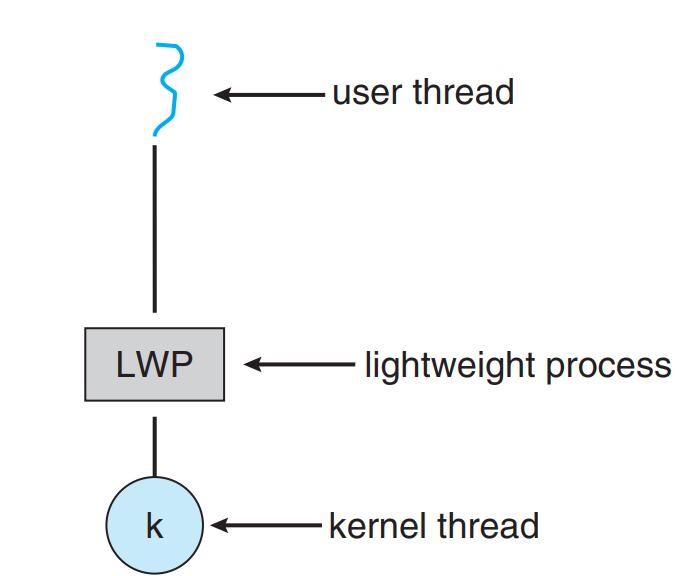
- The application is supplied with a number of kernel threads by the kernel and then the scheduler chooses which thread to assign which work.
- This choosing procedure is called
upcalland its events are calledupcall events.
1 2 3 4
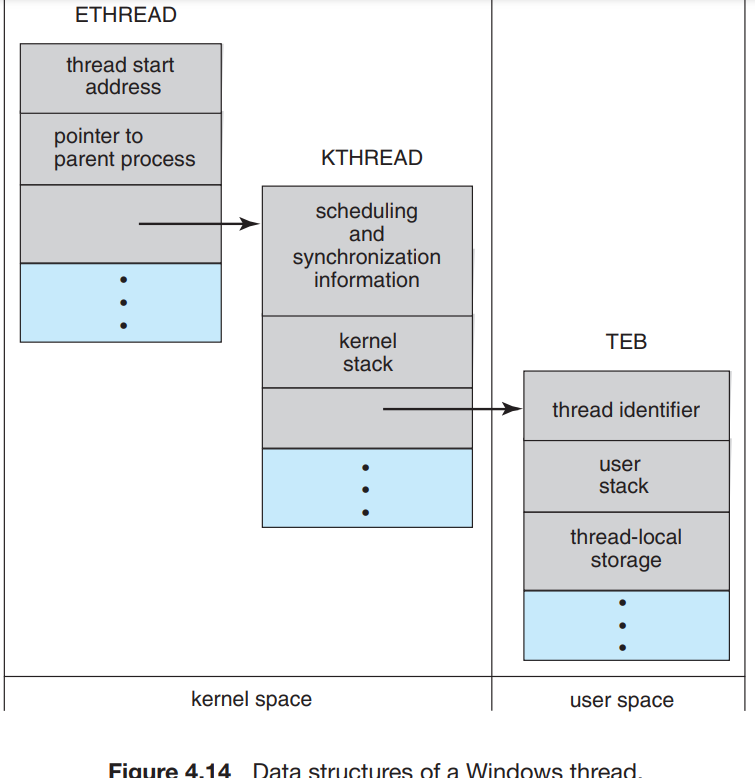
The primary data structures of a thread include: • ETHREAD—executive thread block • KTHREAD—kernel thread block • TEB—thread environment block
- ETHREAD
- ETHREAD include a pointer to the process to which the thread belongs.
- KTHREAD also points to the ETHREAD.
- KTHREAD
- It includes synchronizing and schedulling info of the thread.
- It includes the kernel thread and the pointer to the kernel stack.
- This directive creates as many threads
Process Synchronization
Copperating process
They can be affected by other processes.
Cooperating processes share logical data resources or else they share files or messages.
The Critical Section - It is the section of a process where the process use its resources and perform operations. - Entry section:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25
It is the section where the program requests entry inside a program's entry section. - Exit section: It is the section where the exit requests from the critical section is made by the processes. - Remainder section: It is the section where the code of the process runs or the actual work happens. - If a process wants to access a critical section: - The entering program should not be inside the remainder section of its own. - The process should not be inside the critical section already. - The entering or choosing entry of the process donot take indefinite time. - Race condition: It occurs when the output of sharing of resources between two or more processes is not as predicted or is non-deterministic. - Ways to handle critical section: - Prempted kernel: It performs preempting execution of the processes. It is to give more priority to highly needed process and skip execution of the current process. - Non-preempted kernel: It performs the process and completes it until it terminates.- Peterson’s Problem
Take a map like structure where the array of processes will have thier own flag variable attached witht them so that thay can exsily load process into the critical section and also make sure that not more than two threads are being worked upon.
If a process wants to enter the critical section then it will first change the attached flag carianle value from 0 to 1 and then enter the critical section of the process in order to
- Synchronization Hardware
- Atomical processes are used to execute instructions without the use of interrupts.
test and set()andcompare and swap()are the instructions used for this atomically uninterruptable instructions.
- Mutex lock
- The process have to access the lock when it wants ot enter into the critical section and then has to release it once it exits the critical section.
- These mutex
releaseandacquirefunctions are atomically executed thus they donot raise interrupts. spinlock()function is to continuously callacquire()in a loop such that it can access the critical section once it is released.
- Semaphore
- It is a variable accessed by the
wait()andsignal()functions. - wait function:
1 2 3 4 5
wait(S) { while (S <= 0) ; // busy wait S--; }- signal function:
1 2 3
signal(S) { S++; } - It is a variable accessed by the
Counting sempahores: They can be used to limit the access of the available number of resources to the processes inside the critical section. Consider:
1 2 3
P1: S1; signal(synch);1 2 3
P2: wait(synch); S2;- wakeup() operation A process that is blocked, waiting on a semaphore S, should be restarted when some other process executes a signal() operation. The process is restarted by a wakeup() operation.
- Sempahore manipulation:
1 2 3 4 5 6 7
wait(semaphore *S) { S->value--; if (S->value < 0) { add this process to S->list; block(); } }When signal is called then the semaphore pointer must be added to point to the next element in the list.
block() operation is to block the process that has called it and wakeup() operation is to again revive it .
wait and signal fucntions are just moving the
busy waitingproblem from the entry section to the critical section of the process.
- Deadlocks
It is the situation where one process is waiting for signal and the other process is waiting for the signal from the first process too. This results in the non-working of both the processes.
Priority inversio
This happens in the systems with more than two level of priorities. The middle level priority inherits the process resources and then use them until it gives them to the high priority level resource.
Suppose that there are three tasks A>B>c with the level of shown priorities:
Here , if the resource is used by the B task while the task C is running then the Task B waits for the Task C to complete while the task A waits for the task B to complete. This causes A that has a higher priority to not complete un less and until C is completed.
- The Readers and Writers
- The writers are the ones that want to update the database while the readers are the one that want to just read and observe the database.

Here we have the reading process that will signal the read() mutex or release the read lock so that the read operation can be performed.
- Reader and wroter locks
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15
def reader(): global reader_count rw_mutex.acquire() reader_count += 1 if reader_count == 1: mutex.acquire() # First reader acquires the lock rw_mutex.release() # Read from shared_data rw_mutex.acquire() reader_count -= 1 if reader_count == 0: mutex.release() # Last reader releases the lock rw_mutex.release()- The first reader is the condition where the data is read by the reader only after the finishing of all the writers finished writing.
- The last reader is to read the data by the reader ans written by the writer simultaneously.
- The Dining Philosopher problem
- All the processes trying to access the reqources and also trying to use them simultaneously then they end up
• Allow at most four philosophers to be sitting simultaneously at the table.
• Allow a philosopher to pick up her chopsticks only if both chopsticks are available (to do this, she must pick them up in a critical section).
• Use an asymmetric solution—that is, an odd-numbered philosopher picks up first her left chopstick and then her right chopstick, whereas an evennumbered philosopher picks up her right chopstick and then her left chopstick.
Monitors
1 2 3
wait(mutex) critical section wait(mutex)This will result in deadlock situation as there are two processes that are waiting for each other .
ADT(Abstract Data Types) They encapsulate data inside the set of functions to operate on them.

- This is one of the solution to the dining-philosophers problem.
- Events They are like condition variables as they can notify the thread whether it can access the resource or not.
Dispatcher objects They are in signaled state or non-signaled state. Signaled state is when the thread will not block when acquiring the object.
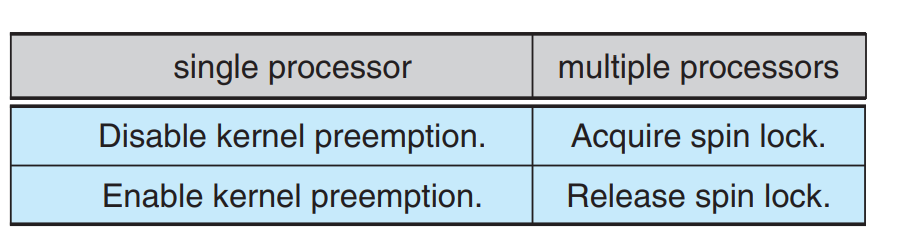
- Spinlocks are not efficient in single threaded kernels thus we use kernel preemption here. -Named Sempahores: They are related to the actual filenames and can be shared between different files or processes.
- Unnamed Sephamores: They are not related to any known filename thus they can be only shared within the same file or process.
Cpu Schedulling
- Peterson’s Problem
- I/O Burst Cycle
- Process execution starts with a CPU burst and then with an I/O burst.
- CPU schedulling occurs at three conditions:
- Ready state to waiting state.
- Running state to ready state.
- Waiting to ready state.
- Process terminates.
- 1 and 4 is done when schedulling is nonpreemptive/cooperative , one process must wait for the other to terminate or call the wait() mutex call.
- 2 and 3 is done when schedulling is preemptive.
A timer is needed for preemptive schedulling because it involves the resuming of another process or starting another process by calling interrupts inside one binary.
Dispatcher
- It is the component that gives control of the CPU to the process chosen by the scheduller.
- It is thus called everytime the process is switched.
- Dispatch latency is thus the time taken by the dispatcher to switch to one process to another to give control of CPU resources.
- Throughput: It is the number of processes that are completed per unit time.
- The only waiting time that is spent inside the CPU schedulling algorithm is the time spent by a process waiting inside the ready queue waiting to be chosen to be executed.
- Response time is the time taken by the process to start giving the output.
- Schedulling Algorithms
FIFO The first process to access the CPU is the first to get access to the resources or we can say to the critical section of the CPU. This can be implemented using a FIFO queue. The PCB block is linked to the tail of the queue.
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72
``` PCB 1- Process State: (Blocked,Waiting,Running or Ready) 2- Program Counter: It has the pointer to the next instruction. 3- Registers 4- CPU schedulling: The schedulling queue and the process priority levels. 5- Memory manager: Info about the memory assigned to the process. 6- Accounting info: Resource usage by the process 7- I/O : the input-output devices that are being used. 8- Process identification: distinguish one process from another.(PID) 9- Next PCB pointer: link to the next PCB. ``` ``` CPU Burst: During a CPU burst, a process is actively executing instructions on the CPU. This is the phase where the process is utilizing the CPU to perform computations and progress its tasks. The duration of a CPU burst depends on the nature of the process and the workload it is performing. Some processes may have short bursts, while others may have longer bursts. I/O Burst: After completing a CPU burst, a process may enter an I/O-bound phase where it needs to perform input/output operations, such as reading from or writing to a file, communicating with a network, or interacting with other external devices. During an I/O burst, the process is waiting for the I/O operation to complete. This phase is characterized by the process being blocked or idle, as it is not actively using the CPU. ``` - It has the link to the next CPU burst and try to find it into the schedulling list. - Convoy effect is when the lower priority processes are allowed before the higher priority processes. -Shortest job first algortihm : It is not much optimal as it includes adding the shortest job in the waiting queue to be added to the ready queue - Time taken by nth CPU burst:  - tn is the time taken by the nth CPU burst.  This is called SJF Preemptive algorithm that is also called the Shortest-Remaining Time algorithm. - When process P1 is scheduled then it is executed but only for 1 second as the process P2 has much less burst time then P4 is executed due to SJF algo. - Priority Schedulling - Equal processes are given priority in FCFS order. - Some systems denote highest priority with 0 while some represent the lowest priority with 0. 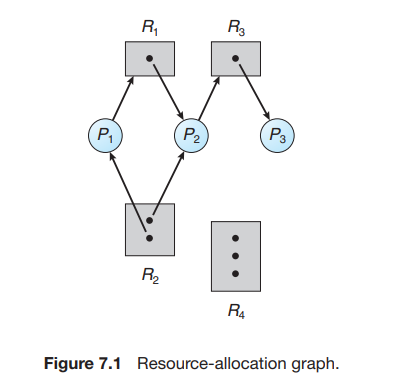 - Here a new process can preempt the running process if any process with more priority is requested by the CPU scheduler. - The problem with this is that it may happen that the low-priority scheduled processes are unable to be completed due to continuously execution of the higher priority level processes. - The solution to this problem is Aging (The processes increase their priority level as they spend more time waiting in the ready queue or the waiting queue.) - Round Robin Schedulling - It is implemented using the timer interrupts. - Circular queue is used here. - Every process will get a particular time to complete the process (time Quantum). If it does'nt execute its work in that time then the scheduler passes the critical section resources to the next process in the queue and then the current process is halted by an interrupt and moved to the tail of the circular queue. 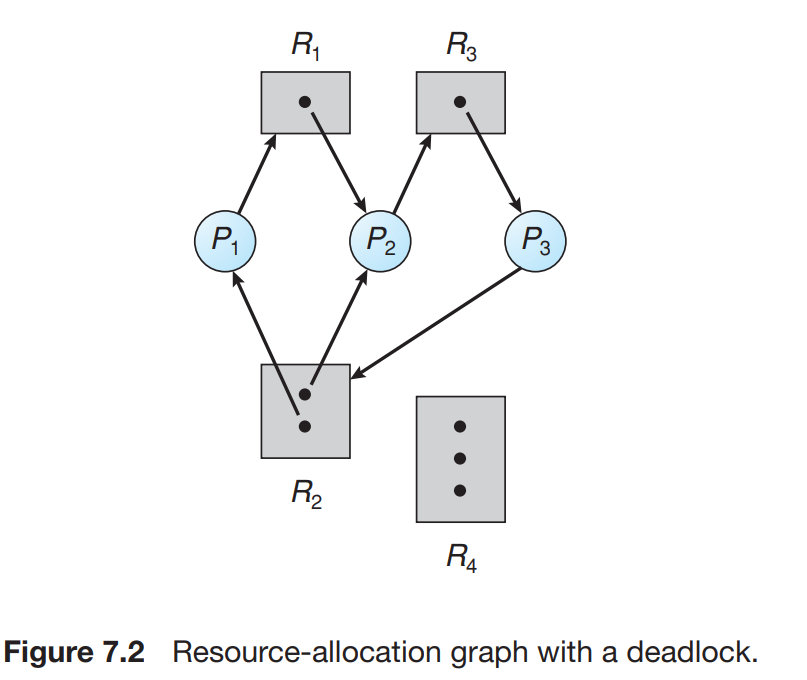 - It is a preemptive algorithm. - If the time quantum is too short then too much time will be spent on context switching and if it is too long then RR will become FCFS schedulling. - Multilevel Queue Schedulling - Many queues partitions are made of the given ready queue in order to rearrange them also in according to a priority level and then different or same algorithms are implemented in the made queues. - For example, if we have a foreground process and a background process then the foreground process will be given more priority and thus the background process can be preempted. 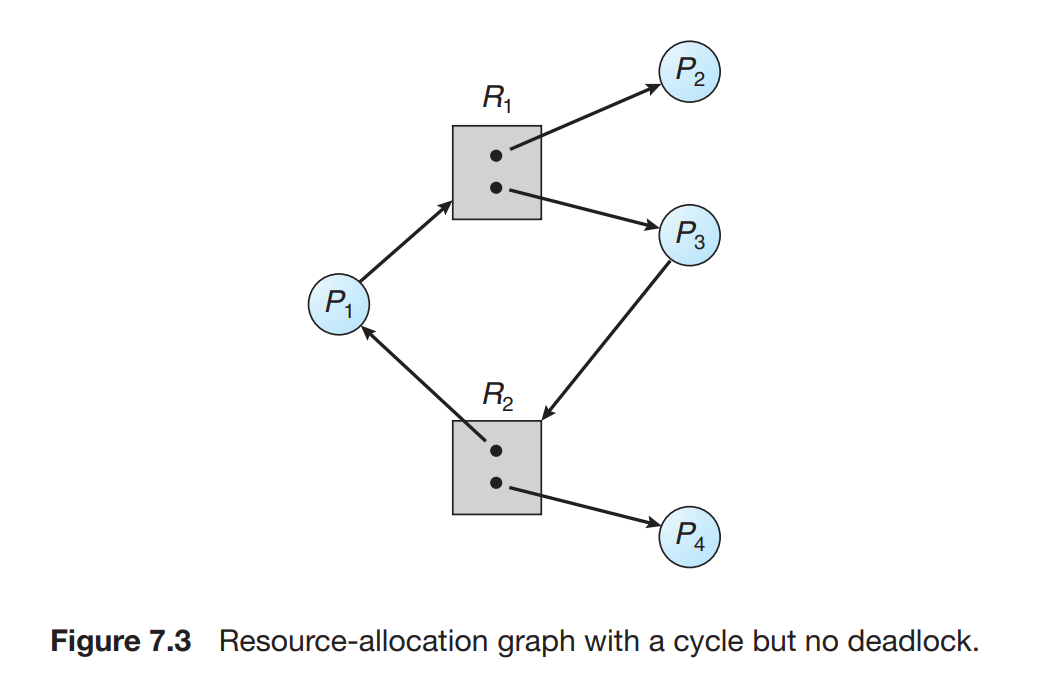 - Multilevel feedback queue - In this algorithm, the process can be moved from queue to another queue based on its CPU burst level and its priority level as it implements aging.- Thread Schedulling
- Process contention Scope The thread library assigns the user level thread to the lightweight process as there is a fight among threads to get the control of the CPU.
- System Contention Scope It is used to choose which kernel thread to execute on the system.
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19
void *thread_function(void *arg) { printf("Hello from the thread!\n"); pthread_exit(NULL); } int main() { pthread_t thread_id; int result = pthread_create(&thread_id, NULL, thread_function, NULL); if (result != 0) { fprintf(stderr, "Thread creation failed: %d\n", result); return 1; } pthread_join(thread_id, NULL); printf("Thread joined.\n"); return 0; } - Multiple Processor Schedulling -Asymmetric mutliprocessor schedulling Only one processor access the system datat structures. -Symmetric multiprocessor schedulling All ahve their own queues or are in a common shared queue.
Processor affinity It is the tendency of the processor to retain the details of the process that is already on it executing and avpoid migration of the processes to other processor as it may raise the issue of overloading or invalid cache memory.
- Soft affinity The CPU tries to retain the process on the same processor
- Hard affinity The CPU tries to retain the process on the subset of the list of processors.
- Load balancing It balances and evenly gives the processes CPU resources to execute.
- Push migration It is to check the processor load on a regular basis and then move the processes likewise as required. -Pull migration It is done by an isolated processor that pulls a process from the busy heavy workloaded processor.
- They both are generally implemented in parallel in the systems.
- Multicore processors
- Multithreading a core processor
- Coarse grained
- It switches between threads at a greater cost.
- Finely grained
- It switches between the threads at a very fine level and this ytakes less time for swtiching.
- In this switching too the urgency of the threads or the processes is compared and then the thread with the highest is executed ahowever both are migrated or moved to other queues.
- Coarse grained
- Multithreading a core processor
Real time CPU schedulling
- Soft real time systems It guarantees that the process will be given priority over other processes but donot guarantee when it will be executed.
- Hard real time systems It ensures that the task is executed before its expiry and if the deadline has expired then the tasks may not be done at all.
- Event latency
- Interrupt latency
- It is the time taken by the CPU to response to the interrupt event cause by the process.
- The CPU has to save the state of the service it was performing and identify the type of interrupt rececived.
- Dispatch latency is the time taken by the dispatcher to switch the processes while schedulling.
- Interrupt latency
- Priority based schedulling
- Admission control algorithm The scheduller either accepts that the task will be completed before time of the deadline expels out or totally denies that the task will never be completed unser the given deadline.
Rate monotonic scheduling
1
The CPU utilization ratio is the time taken by the CPU/Process CPU burst.
- The more priority is assigned to the processes that have less CPU burts time.
- The processes are run till the deadline time un til it is preempted by the processes that have more priority or simply have kless CPU burst time.
- Earliest Deadline First schedulling This assigns the schedulling order according to the deadline time of the processes. Here,Priorities are adjusted according to the deadline of the system unlike rate monotonic scheduling that has fixed priorities for all the processes once added to the waiting queue.
- Proportional Share scheduling
- In this a proportion of the system or the CPU processor is given to different processes and it is proprotional to the percent of CPU required by the process.
- But the disadvantage in this is that if a process that requires more percent of the CPU that is available tries to enter the CPU system or access the resources of the critical section then the admission control policy denies entry to it. -POSIX Real Time Scheduling
- There are two classes of POSIX threads that control tis scheduling -SCHED_FIFO Schedules according to the FCFS strategy. -SCHED_RR Schedules according to the roun robin startegy.
- SCHED_OTHER Schedules according to any strategy of scheduling that may be different on different OS.
- Completely Fair Scheduling
- It is used in Linux systems
- A nice vlaue is attached to all the processes in the system and then the more the nice value lower is the priority.
- Here targeted latency is used instead of time slicing. It is the time duration in which all the tasks should be run atleast once.
- Virtual Run time(vruntime)
- It is the time or can be said a variable calculated for each process .
Calculation:
First the time is calculated for the process runtime on the system and then the decay rate depending on the process priority is used. The more the priority of the process higher is the decay rate.
- Then the scheduler selects the process with the shortest virtual runtime to execute.
- Here a red black tree data structure is used to implement the tasks as the shortest vruntime processes are added at the leaf nodes of the tree.
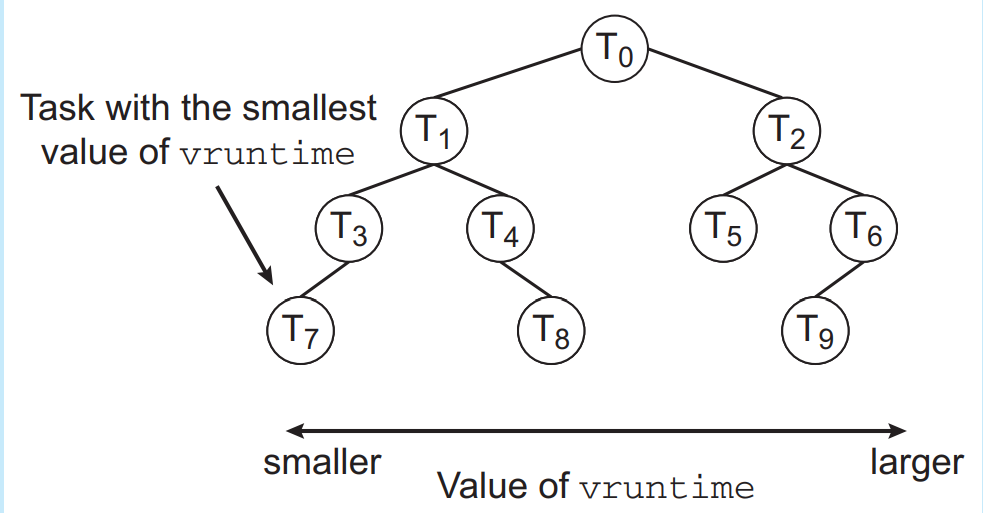
- The dispatcher executes the idle thread in case if no thread is available to execute.
1 2 3 4 5 6
• IDLE PRIORITY CLASS • BELOW NORMAL PRIORITY CLASS • NORMAL PRIORITY CLASS • ABOVE NORMAL PRIORITY CLASS • HIGH PRIORITY CLASS • REALTIME PRIORITY CLASS
By default the processes are under the Normal Priority unless its parent process is under IDLE priority.
SetPriorityClass() function is used to set the priority of the processes.
The REALTIME priority is the one that cannot be changed.
- SetThreadPriority() functions can be used to modify the thread’s priority.
- Windows 7 introduced UMS (User Mode Scheduling) that is when the dispatcher allows the threads to be executed without any kernel intervantion and in the user system.
Algorithm schedulling




Little’s Formula n = average queue length lambda = avg arrival rate for new prcoess inside the queue. W = avg waiting time of a process inside the queue.
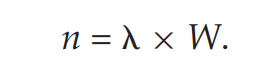
- Thread Schedulling
Deadlocks
It is the situation in which one process cannot execute until and unless the other process is executed and the other process cannot be executed until the first process is executed.
1 2 3 4 5
The pthread mutex init() function initializes an unlocked mutex. Mutex locks are acquired and released using pthread mutex lock() and pthread mutex unlock(), respectively. If a thread attempts to acquire a locked mutex, the call to pthread mutex lock() blocks the thread until the owner of the mutex lock invokes pthread mutex unlock().
- Necessary conditions for a Deadlock to occur
Hold and Wait:
A process is holding atleast one resource and waiting for the remaining resources from the other held processes that are held by much other processes/
Circular waiting:
1
P0 is waiting for the resources from P1 that is waiting for the resources from P2 and then so on.
No preemption:
1
A resource cannot be preempted by the another process, it will be released only if the task is finished.
Mutual Exclusion:
1
The resource can be only used by the process until and unless it is not released by the another process.
Resource allocation graph
Let Pi denote all the Processes and Rj denote all the resources then :
Pi -> Rjis calledrequest edgeandRj -> Piis calledassignment edge.- The dots in the rectangles are the instances of the resources within the resources.
The rectangles are the resources and the circles are the processes.

Cyclein a resource allocation graph depicts adeadlock state.

- The graph is in the cycle is not a sufficient condition for the deadlock state of the system.

- Here the process P4 can release the process instance R2 and then can be used by the other process P3.
Handling deadlocks
Generally most of the OS ignore the deadlocked state and it is up to the oser to make the program avoid deadlock state in it .
Whenever a process requests a resource then it must not hold any other resources.This will stop Hold and Wait condition.
Whenever a Non-sharable resource is trying to be shared then mutex occurs. Thus sharable resources are required to eliminate the mutex condition. For ex: Read files can be shared by many systems.
- Witness is just like a method that prevents deadlock , it gives warnings when the system has executed processes or have resources out of order

Deadlock avoidance algorithms
They can be avoided by ensuring that the circular wait condition never occur.
Safe state: If the system allocates resources in an order and still avoid deadlock condition. The process is in the safe state if a safe sequence of the processes exist that is all processes can be assigned resources that they are demanding and all the resources that are being held by the processes.
- An unsafe state leads to a deadlock state.
RAG for deadlock
Claim edge:
- It depicts that the process may request the resource in the future.
- It is represented by a dashed line and is similar to a request edge.
Banker’s Algorithm
When a new process is trying to enter into the queue then the CPU checks the maximum no of instances of the resources it may need, it should not be more than the total resources available.
When a user requests resources then the system determines whether the process will leave the system at a safe state or not if it does’nt then it must wait for all other processes to finish working woth the resources.
Recovery from Deadlock state
One way is to abort some of the processes in order to break the circular wait of the processes where they are dependent on each other.
The termination of the programs in the deadlocked state is a decision similar to CPU scheduling process as it requires the least cost causing process to terminate.
Termination depends on :
Victim Selection:
The process that has the minimum termination cost is to be selected to terminate as it will utilize much less resources and time. It also depends on the time that the process ahs already consumed.
Rollback
We can roll the process back to its safe state
Memory Management
Main Memory
Registers are accessed in one cycle of the CPU while the CPU main memory is accessed on every transaction of memory bus.
Any program that is running in user mode but trying to access the OS system results in a trap that halts the program then and there.
This is used to prevent the program running in user mode to modify the resources or data structures of the memory or of the other users.
Only the OS is allowed to load the required limit and base registers.
Address Binding
The processes have to be migrated to and fro the memory and the disk. The processes that are waiting to be brought into memory for execution are stored into the input queue.
Binding is the process of giving or extending the addresses of the memory of the executable files.
The compiler does this in compile time when it is certain of the location of the file and its memory and its other details.
Load Time:
If it is not known by the compiler that where will the process will be placed in the memory then the program makes a relocatable memory.
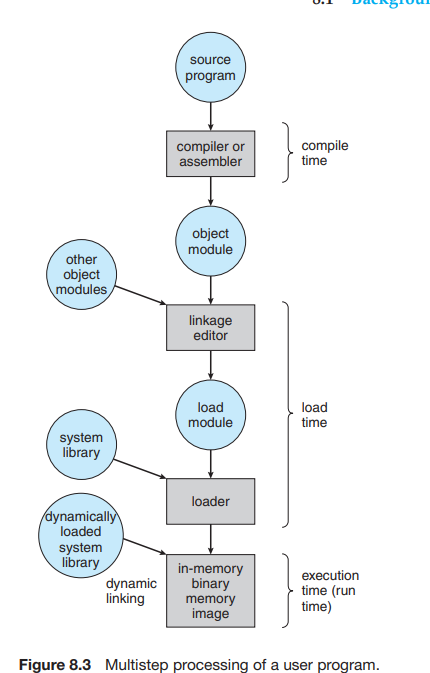
The starting addresses have to be changed as soon as the addresses of the binary executable of the later section changes.
Logical and Physical Address
The address generated by the CPU is called logical address while the memory-address register inside the memory holds the Physical address.
The MMU (Memory Management Unit) is responsible for the runtime mapping of the virtual and the physical addresses.
The base register is made a relocation register by the MMU as the address of the memory of the Base register is set as dynamic and when the user tries to find any address inside the executable then it is relocated to the actual address. [If 14000 is the address of the base register then to seek the memory address at 0x0 we will be relocated to 14000 address.]
Logical addresses are the one used by the user directly . They are not the real addresses of the memory data. They vary from 0 to MAX.
Physical Addresses are the ones that are obtained by loading the logical addresses into the memory and also adding the base register address value to all the logical addresses. They vary from (base_reg+0 TO base_reg+MAX).
Dynamic Loading
It is to load a routine only when it is called by the program. Till then it resides as a relocatable code.
It helps in managing the big chunks of code and the code that give errors on loading simultaneously with other priority processes.
Dynamic linking and loading Libraries
Static linking is not much beneficial as it is actually the combination of the image bianry executable.
It is a very crucial task as else every executable must have to attach its own library for basic things like language,writing output,etc.
There is a stub located inside every library for reference to be provided to the executable programs that may load the same library again at another time.
Dynamic loading is different from dynamic linking as in dynamic loading the library is loaded dynamically during the execution of the executable and the shared library or the dynamically linked library is the one that is attached to the executable program only if the executable is compiled to have them attached.
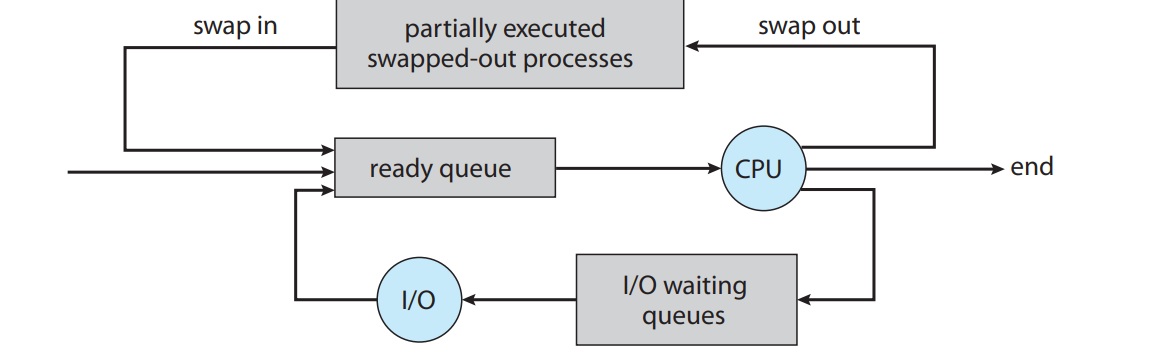
- Swapping
- This involves storing the memory into a backing store and then taking it back inside the executable to use it.
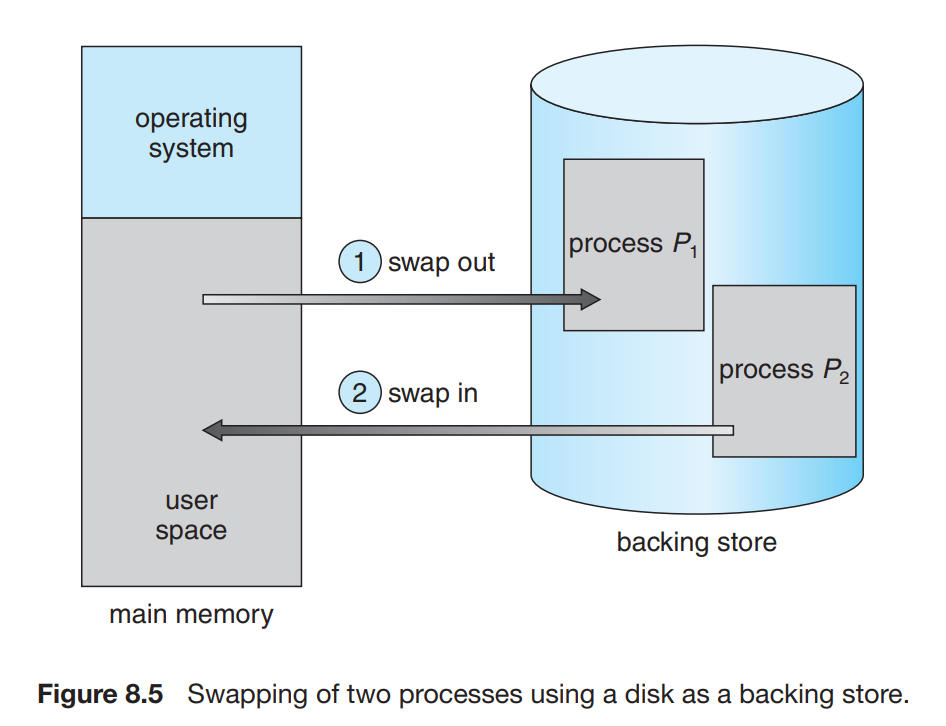
The processes inside the memory backing store are also stored inside the ready queue.
When the dispatcher is ordered by the scheduler to choose a task to be executed then it checks whether the process in the queue is in the memory disk and then if it is not and there is no free memory region then the dispatcher swaps the process of memory with the process in the ready queue and execute it first by loading all the registers and the stacks again.
Swapping can only be done on the files that are idle. Many modern OS systems use the standard swapping algorithm that requires too much time to be executed.
Swapping in IOS
- The program applications are swapped in and out of the flash drive and instead of terminating all the components it retains the basic components like stack in the running memory to execute the applications.
Swapping in Android
- The program applications are not swapped but the program that is not able to free much memory space is temrinated by the android OS while it saves the currenbt state of that application inside the flash memory to be able to execute the application later fast.
Contiguous Memory Allocation
It is to allocate an initialised or non-initialized bytes in the memory that is contiguous to the next process memory.
The dispatcher is the one that loads the limit registers and the base register to be added to the addresses of the memory.
The relocation register helps us in using the transient code that is the program code that comes and goes dynamically due to the dynamic loading or linking.
Memory Allocation
The memory is allocated to a process using the available space that can be depicted as holes that may combine into two if they are adjacent enough.
The solutions to the problem of memory allocation are:
First Fit:
As soon as we find the enough big hole to give it to the process we assign the space to the task. However the searching begins at the start or the end of the previous first fit search.
Best Fit:
It is to find the smallest big enough hole among all the holes that can be used to assgin the task.
- Worst Fit:
Fragmentation
It is the problem that arises when we have enough total memory space to assign them to the tasks but it is divided into chunks that if are combined into one can be used to perform the task as an individual.
50-percent rule states that even after many optimization techniques the half of the memory will be wasted due to external fragmentation.
One solution is to push or place all the processes on one side and then the holes come up towards the other side and then they will be able to combine easily.(This is called compaction).
Second solution is to make the logical addresses of the memory non-contiguous and then the memory can be assigned wherever it is found and not necessary must be contiguous. Here the logical address of the memory is not identical to the physical address of the memory.
Segmentation
The memory is divided into a number of segments that are used as required. They can vary in length and space and functions. Also they have no physical addresses, instead they have offsets that are used to identify them inside the binary executable file.
- Each address have two components:
<segment_name>,offset. The 2d addresses of the user are converted to the 1d addresses of the physical memory.
Segmentation hardware
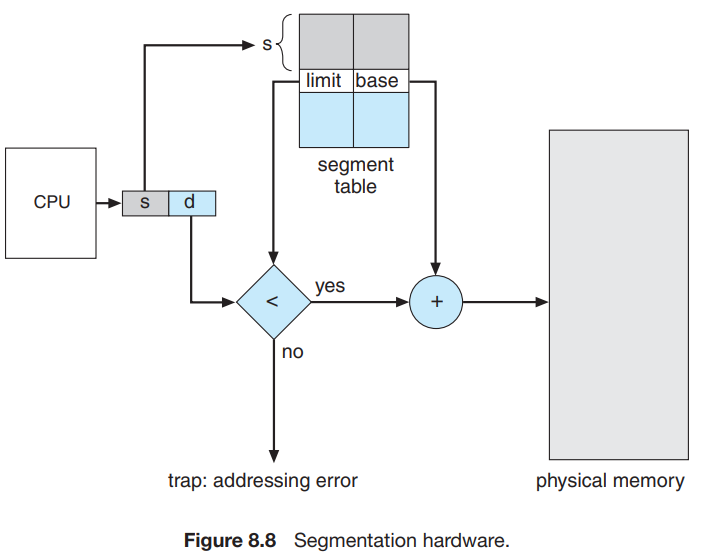
- This segments are stores inside the segment table.
- Each entry inside the segment table has a segment base and segment limit.
Segment base is the starting of the physical addresses of the program and the limit is the length of the segment and the segment are the ones that reside in the memory.
A logical address has 2 components: Segment number and the offset (this offset serves as an index that lists it inside the segment base till the segment limit).
The segment number is the index to the segment table
For example, segment 2 is 400 bytes long and begins at location 4300. Thus, a reference to byte 53 of segment 2 is mapped onto location 4300 + 53 = 4353. A reference to segment 3, byte 852, is mapped to 3200 (the base of segment 3) + 852 = 4052. A reference to byte 1222 of segment 0 would result in a trap to the operating system, as this segment is only 1,000 bytes long.
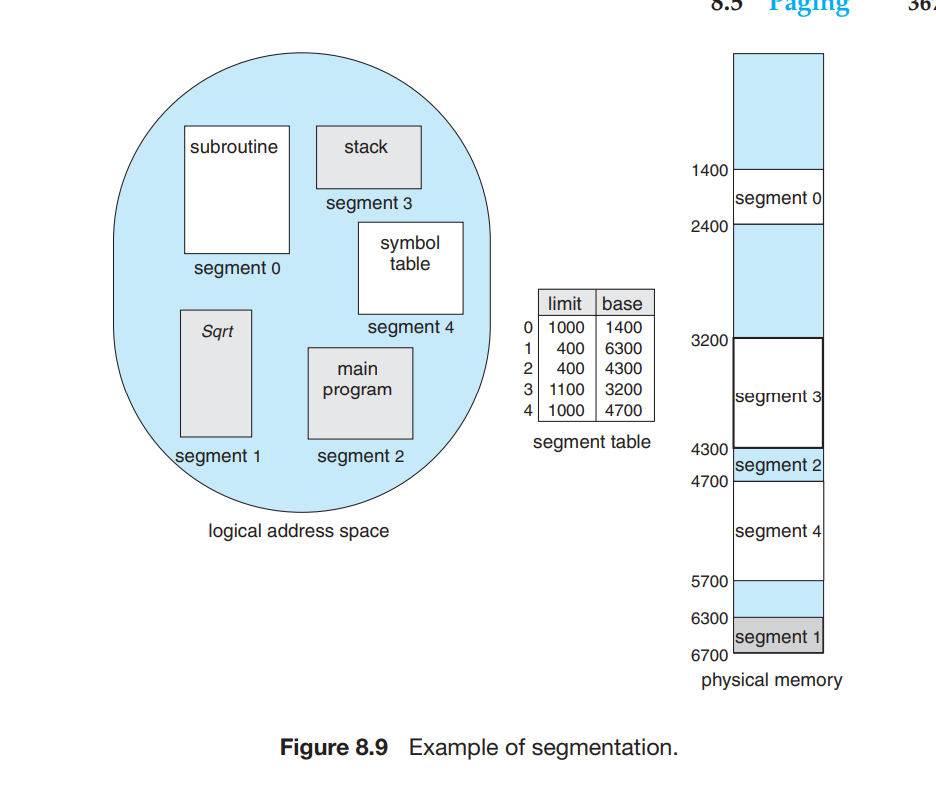
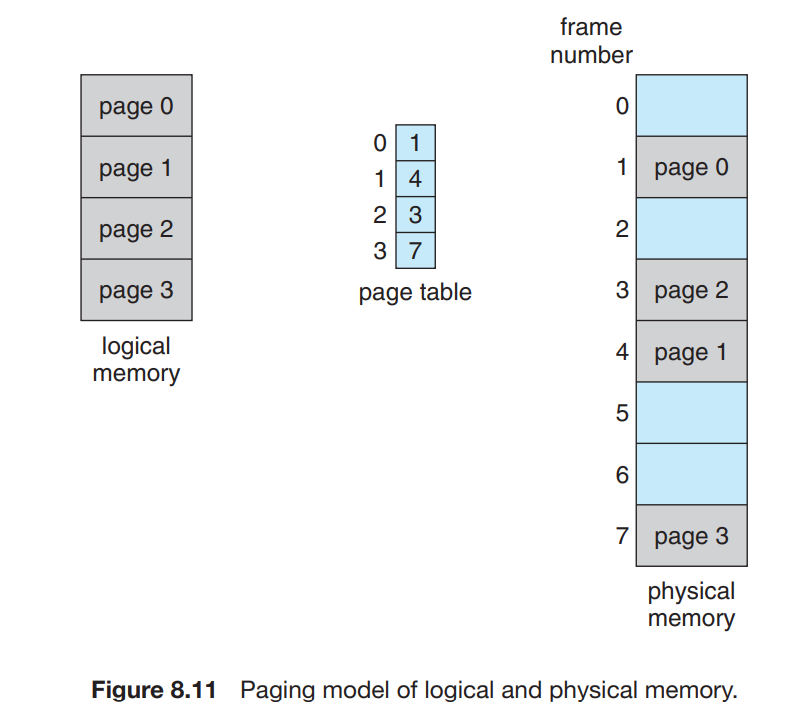
Paging
It also gives us the feature of mapping the addresses as non-contiguous. It is generally used in most OS systems.
- Physical memory is broken into pieces called frames and the logical memory into pages.
- Every address have the page number and the page offset.
- The page number is the index inside the paging table.
- This page table stores the base address of each page inside the physical memory.
- The base address combined with the page offset gives us the physical memory address inside the memory unit.
- The page size and the frame size is always same as they have to be fitted inside each other.
- It is a type of dynamic relocation.
- We have eliminated the problem of external fragmentation as we can allocate the pages in any frames. However internal fragmentation can still occur at small scale.
- The internal fragmentation will occur if the physical memory assigned is more in space than the pages total size required that will result in the partially empty last frame.
- The process can only access the pages inside the pages table that accesses the physical memory frame to get the data stores inside the pages inside the frames.
- The Frame table contains the information about the frames whether they are available or whether they are allocated.
- The CPU have to maintain a copy of the page table , Frame table as well as all the registers and their contents.
- Thus Paging increases the context-switch time and thus makes it slow.
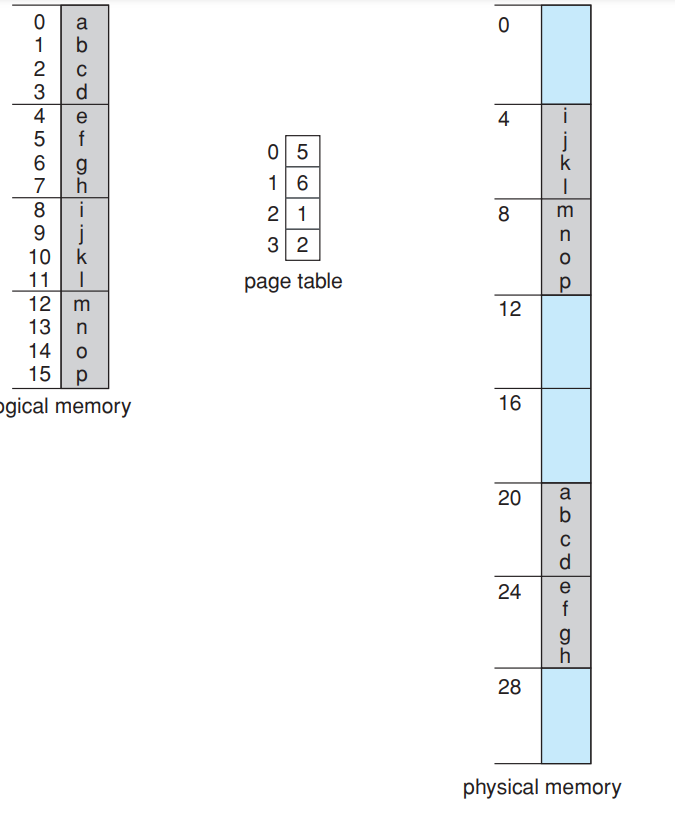
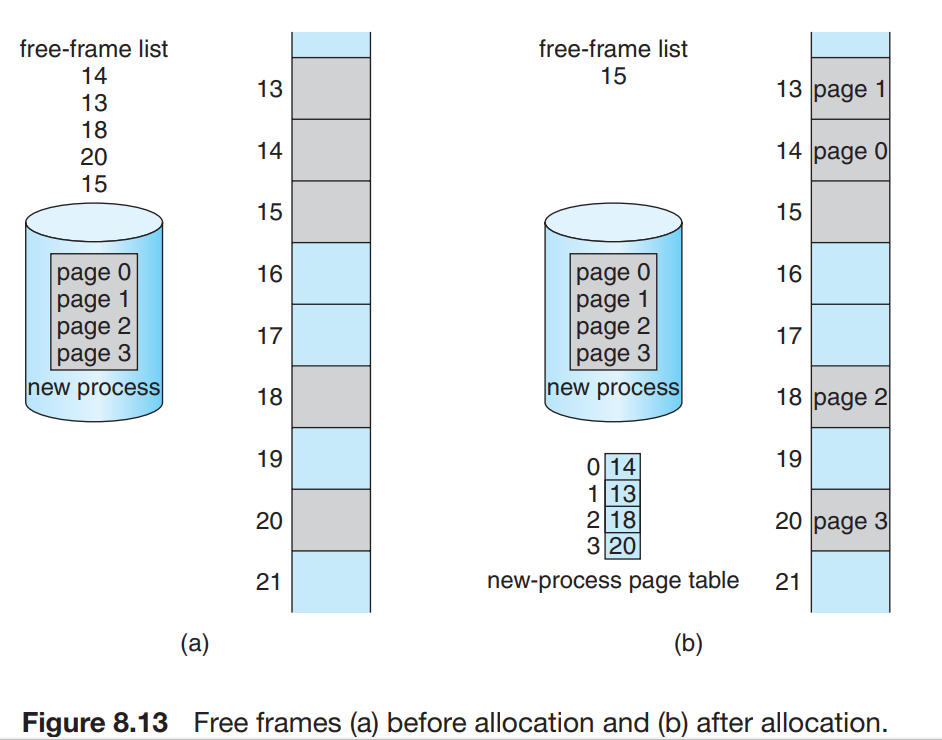
Hardware Support
The page table is stored at an address and a pointer to the page table is stored inside the Process Control Block along with the registers and instruction counters.
1 2 3 4
Page Faults When a process tries to access the page that donot exist inside the RAM memory. This can be prevented by swapping of pages between main memory and secondary storage.TLB(Translation Lookaside Buffer) is the hardware cache that stores the subset of the page table. It uses to speed up the process of mapping of addresses.
To make the page table mapping speed higher, we use registers to either point to the page table or store the whole page table.
The Page Table Base Register(PTBR) is the one register that points to the page table.
The problem with the PTBR is that we have to first map the page table through the PTBR pointer and then we have to go to the frame table using the page table and then go to the actual address using the page offset to produce the actual physical memory address.
TLB is the solution of this problem:
It is like a dictionary in python that has key and values. TLB lookup is the process that finds the value of the key corresponding to the item that the process provides.This uses instruction pipeline that makes the lookup more faster.
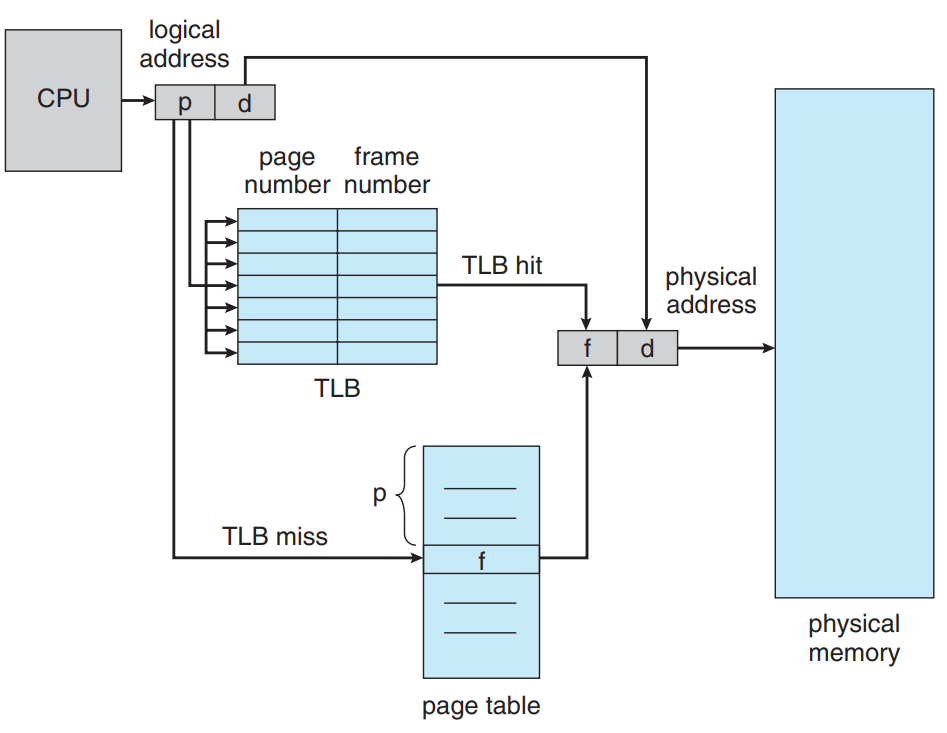
- The CPU has the logical address of the data that has the page number and the page offset .
- The page offset is stored and the page number is mapped to the page table.
- If the page number is not found in the TLB it is a situation of TLB miss that results in the mapping of the page number to the page table directly through an interrupt of the CPU or automatically. The TLB then is mapped to the physical memory in addition with the stored page offset.
ASID(Address Space Identifiers)
It is a unique id stored with every address entry and provide protection to the data addresses of the TLB.
It is defined for each running process and then if the ASID of the running process donot match with the actual active process then the process is encountered with TLB miss case.
Thus we can also find the pages aside from TLB but it will take much more time than the TLB spped up process.
The percentage of times the required page is found inside the TLB is called hit ratio.
Protection
- A bit is stored with the page inside the frames that identify whether the data is read-only or read-write both.
This bit is also read at the time of the storing the page inside the frames. If there is an attempt made that goes against the protection bit permissions, then a hradware interrupt is triggered.
Structure of the Page Table
The page table cannot be stores contguously and thus it is stores using some algorithms inside the main memory:
Two level paging Algorithm:
- The page tables are also paged.
- First we access the outer page table and then that is used to access the inner page table that is the page of page tables.
- Then we are able to access the memory addresses inside the main or the physical memory. - This is also called forward-mapped paging algorithm.
Multilevel paging algorithm
- In 64-bit or more bit systems we have to reduce the size of the outer page table and thus we page the outer page tables again and again. This results in seven level paging inside 64-bit systems that makes it very inefficient for the CPU and slows down its working.
Hashed Page Table
- These are just like hashmaps.
- They contain information about the linked lists containing the page tables and the mapping of the pages inside the linked list.
- They have its first head element as the virtual page number that have to be matched first to follow that path of the pages’ data.
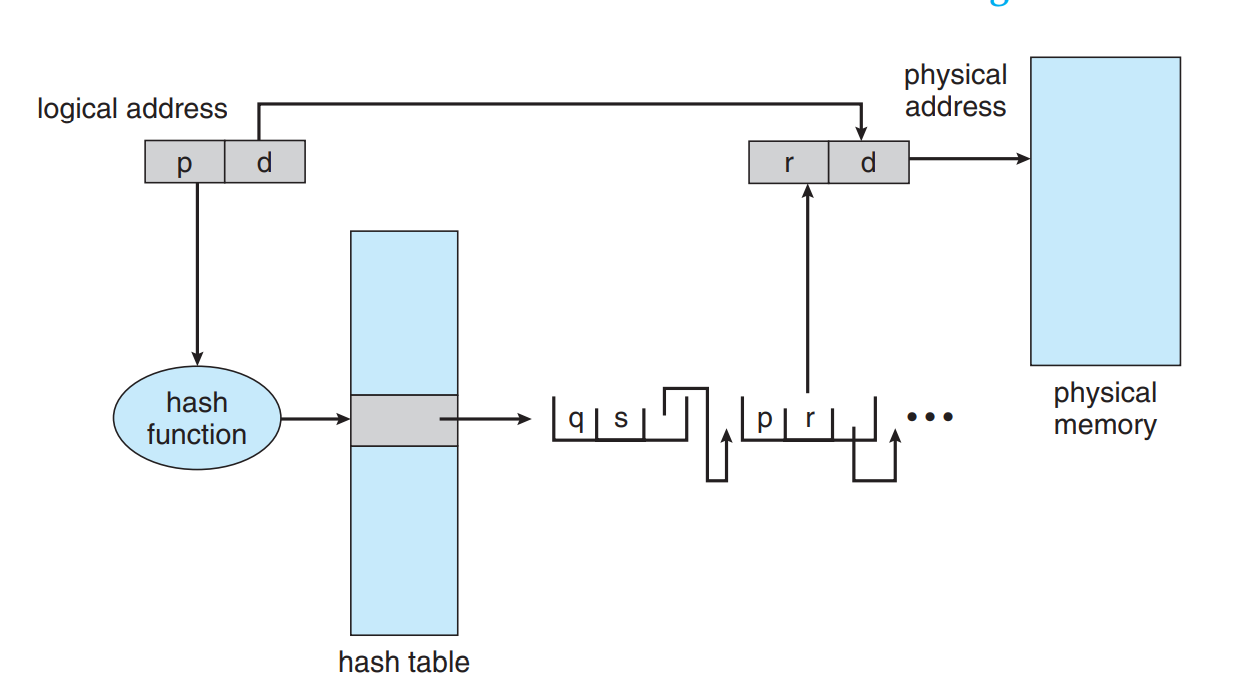
Inverted Page Tables
- They have mapped memory according to the ASIDs and the processes are sorted randomly inside the page table.
- The process-id is used as an ASID for each of the process.
- <pid,pagenumber,offset> is the format of the inverted page table entry.
- They are much inefficient but takes a long time to find the required entry inside the page table as it actually have to find the required process inside the physical memory.
MAIN MEMORY FINDING PROCEDURE

ARM architecture
This has two levels of TLBs:
The outer level has two micro TLBs that store the addresses and instructions separately and then they map to the Main TLB that have data stored inside.
If there is a miss at the micro TLBs then the main TLB is checked if there is a miss in the main TLB too then the page table walk is executed to find the address or else the hardware interrupt is triggered.
Intel Architecture
- Even the programs that are larger than the physical memory can be executed as they donot need to be loaded into the memory directly
- In the same response time, more larger programs can be loaded into the virtual memory with virtual addresses and components.
- Less I/O operations would be needed as less swapping operations will be needed.
- Virtual address space is a contiguous space of memory addresses.
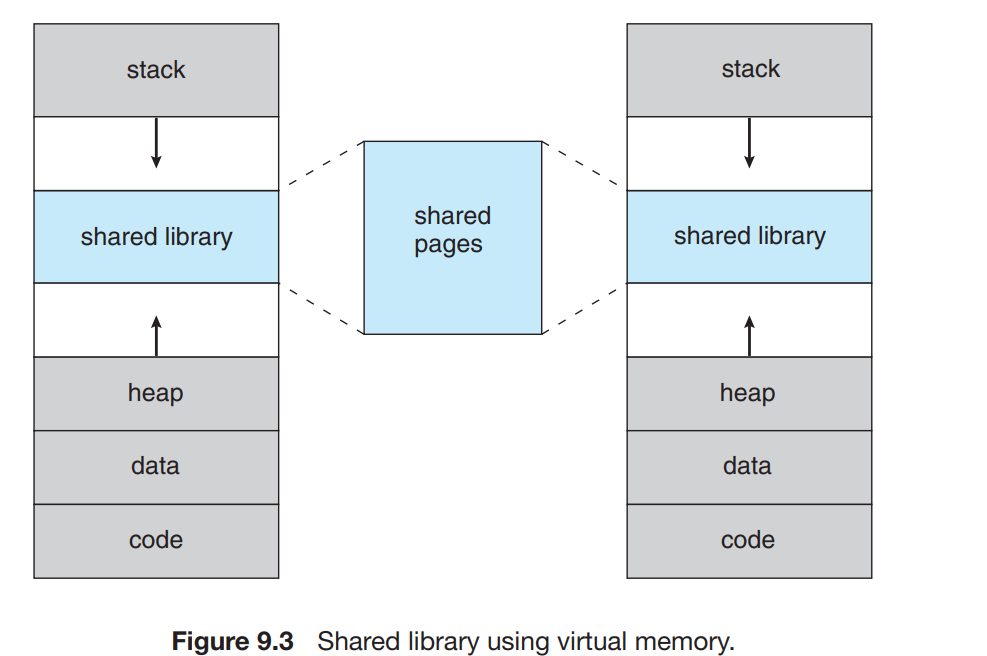
- Here we can easily see how stack grows downwards while the heap grows upwards.
- Virtual address spaces that have holes or is non-contiguous is known as sparse address space.
- System libraries can be shared using this virtual space among the processes.
- Processes which want to share the virtual space to share some memory communicate via these shared regions however the actual pages of physical memory are still shared.
Pages can be shared using
fork()system call.- Demand Paging
- This is to load the pages that the user require only and not load the unnecessary pages to save time as well as memory.
- The pages that are not required are not loaded into the physical memory.
- This is done by
pager. - The process is swapped in as usual but during the swapping out of the process, the pager only swaps out the pages that can be used by the process and thus reduce the time that is wasted in reading the pages stored in the memory that are not going to be used in the recent time.
- The pager distinguishes between these pages through protection bits:
validbit means the page is in memory and is legalinvalidbit means the page might be legal or illegal but is not present inside the memory.
- Page Fault
It occurs when the process is trying to access the page that is not even inside the memory.
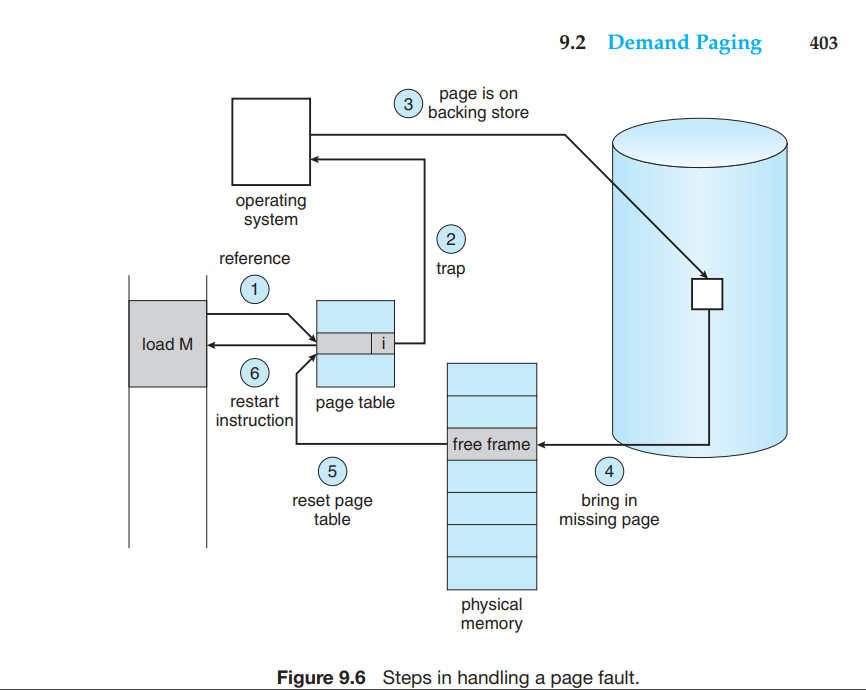
If Page Fault occurs then, hardware trap is triggered and then the page inside the backing store or the secondary storage is retained back into the page fault and then the page table is reset. But this occurs only when the page was valid but not present inside the memory.
- The backing store is actually a secondary disk or can be called
Swap Spacethe space that can be swapped. - If the interrupt occurs when the
FETCHinstruction was getting executed then we have to again call theFETCHinstruction and execute it however in case of anoperand fetchingwe have todecodethe instruction again and then load the required page. - Problem arises when a single instruction is trying to modify multiple number of bytes.
- This can be solved using temporary registers to store the values of the memory so that they can be again reloaded into the page table
- Effective access time is directly proportional to the page fault time.
- The file image is loaded into the swap space and then it is swapped into the memory as required by the process.
- Another option to this is to write the memory data into the swap space as the pages are loaded and replaced and intially load the whole file into the memory directly.
- Copy-On-Write
- We have to reduce the number of pages that must be carried by the new process which is spawned by the
forksystem call. The
forksystem call spawns a process that will have the same page resources as the parent process. If either process writes in the shared pages of both processes then those shared pages are copied for both of the processes.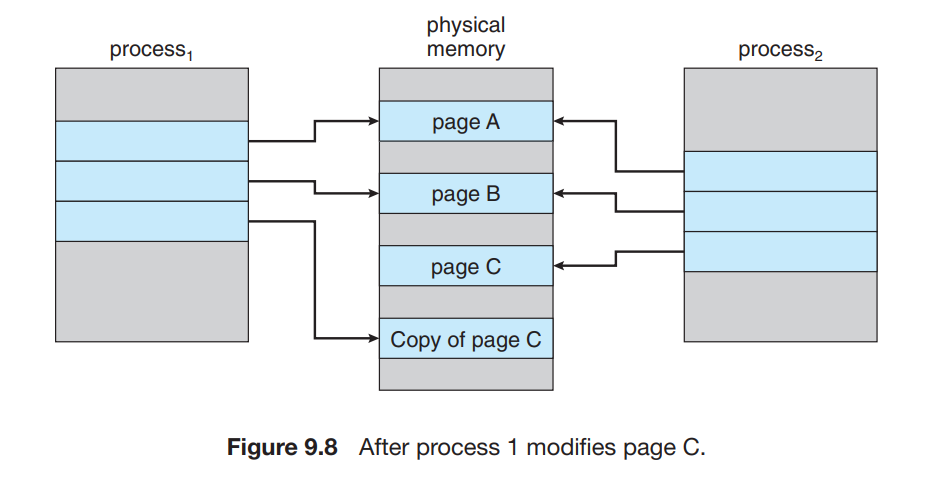
- The above image shows the copy of Page C when it is overwritten by the CPU.
vfork()is the system call that creates a process in virtual space but it does not use copy-on-write and thus if the child process alters the shared pages then the altered pages will appear for the parent process once it resumes to work again.- Thus
vfork()is generally used in the case where the child process is callingexec()system call as it can be used to execute shell scripts. forksystem call is slower but safer as it maintains a copy of the shared pages that ensures that if the child process alters the memory then the parent process will retain the actual memory.
- We have to reduce the number of pages that must be carried by the new process which is spawned by the
Page Replacement
- When the page fault occurs then the CPU must take the page out from the secondary storage memory to the physical memory frames but if there are no
free framesthen the CPU will have to replace a page with the recently required page causingpage replacement. - The page that ia moved out of the memory is called
victimpage. - The page replacement algorithm is executed idf there are no free frames for the desired page.
- If the page has to be replaced then the page fault occurs two times when the page goes out and twice when the page goes in the memory.
Modify bit
- This bit is associated with all the pages and tell us if the page has been modified or not.
- If the page has
modify bit = 0then the page has not been read into the memory and thus it does not need to be written inside the memory. - If the page has
modify bit = 1then the page has been modified after it was read from the memory ans thus has to be written inside the memory again. - Frame allocation algorithm is required because of the frame allocation required when the pages have to be replaced and also determine how many frames to be allocated to each process.
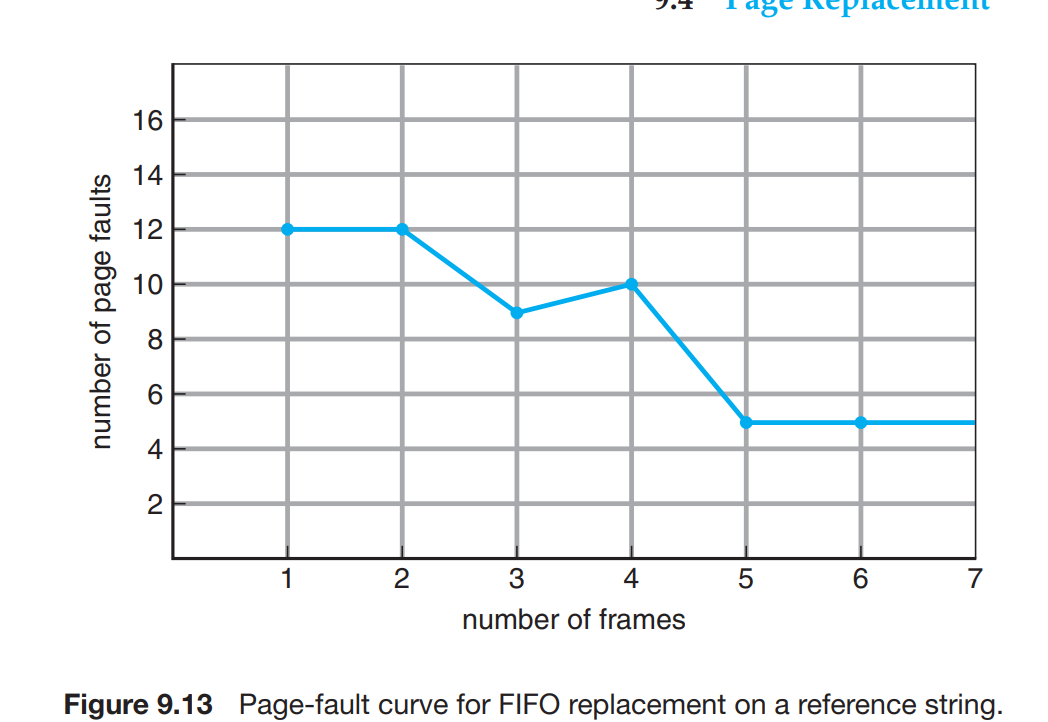
- Reference string is the order of the page references made by the processes on the system.
- As the number of pages increase the page fault also decreases inside the memory.
Page Replacement Algorithms
FIFO
- When a page has to be replaces then the oldest page is chosen to be taken out of the memory.
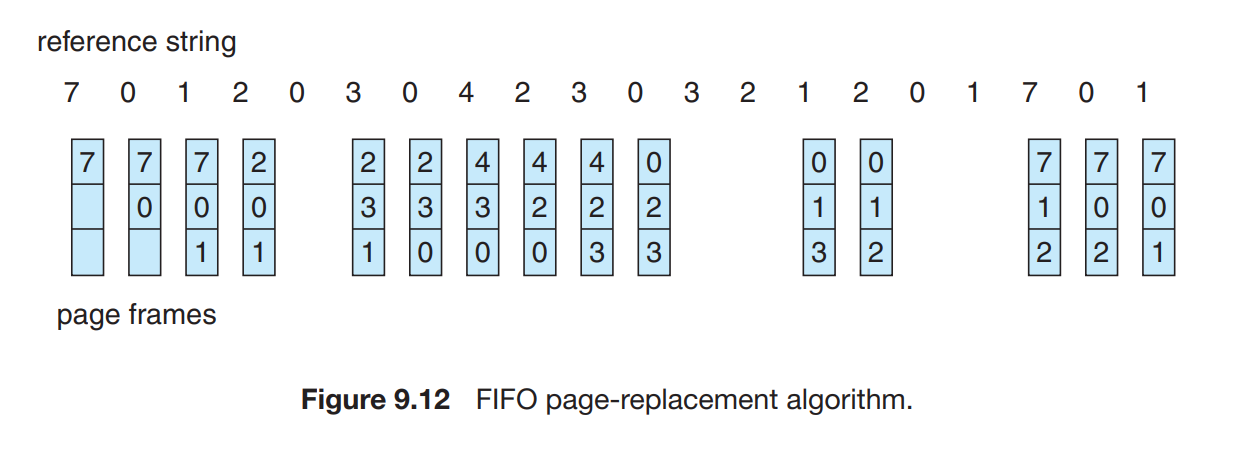
- The fifo page replacement algortihm always replace the pldest reference and never replace if the reference is already inside the reference queue but also in reference string.
Belady’s Anomaly There is an unexpected increase in the page faults when we incerase the number of allocayed page frames from 3 to 4.
Optimal page replacement algorithm
Replace the page that has not been used for a very long time.
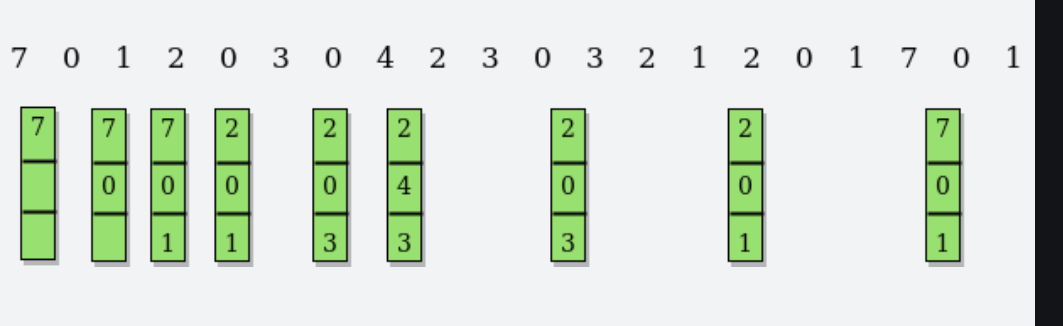
If the page reference already exists inside the queue then the count is incremented unless the page reference that is referenced most later in the future is replaced.
First 7 is replaced as it is again referenced just at the last of the reference string then the
1is replaced as it is referenced at most later in the reference string.
LRU Page replacement algorithm
The FIFO uses the time the page reference has used inside the reference string while the OPT uses the time in which the page reference will be used from the reference string.
This algorithm replaces the least recently used page or the page reference that has not been used for a very long time.
The counter is incremented for every page reference inside the reference string. This can be used to store the time of all the page references and thus decipher which page reference was used least recently
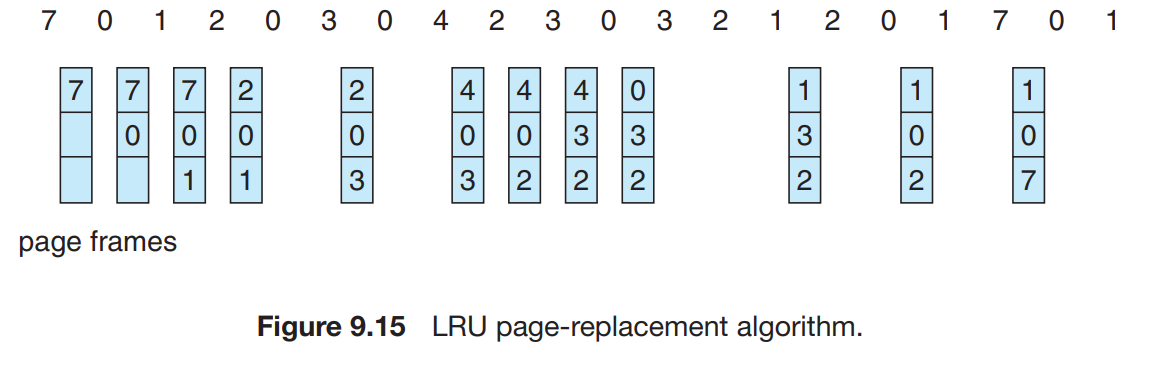
Stack approach:
The page references can be stored inside the stack and then the top one will store the most recent while the bottom will have the least recently used page regference.
This approach is never affected by the Bedaly's Anomaly.LRU Approximation
- Reference bits are the bits that are set for the pages that have been referenced and all of the pages are initially .
Second Chance Algorithm
- If reference bit is 0 then the page is replaced immediately but is the reference bit is 1 then the page is given a second chance and then the FIFO is executed to get the bottom out of the
circular queue.
- If reference bit is 0 then the page is replaced immediately but is the reference bit is 1 then the page is given a second chance and then the FIFO is executed to get the bottom out of the
Enhanced Second Chance Algorithm
- Here we observe the modify bits and the reference bits.
(0,0) : This is the pair that depicts the page not recently used as well as nor modified. This is the best page to replace.
(0,1) : This is the pair that depicts the page that needs to be written before replacement. This is not recently used but is modified.
(1,0) : recently used but clean as it is not modified. This is probably gonna be used by the process soon.
- (1,1) : recently used and modified. This needs to be written out to the memory or disk before the time at which it will be loaded into the disk memory.
Counting based page replacement Algorithm
Least Frequently used
The actively used page should have a large reference count and has been used lewast frequently.
Most Frequently used
The most recent page used generally should have a lower reference count and has not been used much and thus have high probability of being used in the future in the reference string.
Page buffering Algorithms
- It is the process of transfer of data between the disk memory and the primary storage.
- There is a pool of frames that ia maintained and then the page is selected that should be replaced.
Allocation of Frames
- There is also a need to allocagte a minimum number of frames inside the physical memory to maintain performance.
- As the number of pages decrease or the frames decrease then the number of page faults increase then the performance decreases.{Instruction is restarted everytime the page fault occurs}
- The indirect references increases the need of minimum pages number that should be in the physical memory. As one memory refere other it indirectly refer the third one and so on.
- This can be prevented by limiting the number of indirect references the pages can make and also keeping a minimum number of pages inside the physical memory.
Allocation Algorithms
Equal Allocation
The frames are distributed equally among all the processes and then the remaining frames are gone to the free frame pool waiting for any page to get assigned.
Proportional allocation
The processes are assigned frames according to their respective size
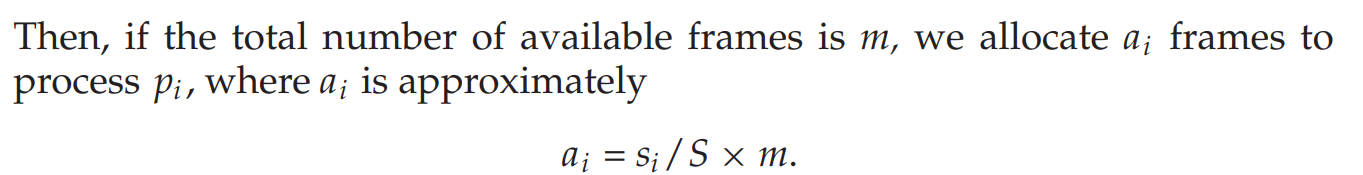
The above both algorithms treat the high priority and the low priority processes same as each other and thus we can also use proportion based on their priorities for proportional allocation.
Global vs Local Allocation
Global frame allocation is the frame replacement where the process can take the frame of any process running or not running.
Local frame allocation is the frame replacement where the process can take the frame of the process only from out of the frames assigned to the process.
The problem with global replacement algorithm is that if the process takes the frame of another process then it may vary in performance and thus may decrease performance.
Non- uniform memory access
This actually means to access the frames of thwe memory that is remote or
far awayfrom the CPU.The uniform memory access is faster than the NUMA and thus our main goal should be to make the CPU come closer to the memory to access the frames faster and efficiently.
Thrashing
If the number of frames allocated for a low-priority process are lesser than required then the process is terminated and the freed frames are given to the free frames pool.
Here the process have to replace the active page of its own that is going to be used again most recently and thus it has to bring the page back again and again and replace the pages again and again that causes performance degradation as the process has to spend more time paging than the execution of the process.
Cause of Thrashing
- As the pages are replaced by one process from another then this chain continues and this results in multiple page faults and multiple page replacements that empties the ready queue and the page replacement cannot be done any further. This results in lesser CPU performance. The scheduler then scheduled multiprogramming processes so that to increase the performance of the CPU but it further decreases the performance if the page faults occur in this process too causing more multiprogramming processes to be scheduled by the scheduler.
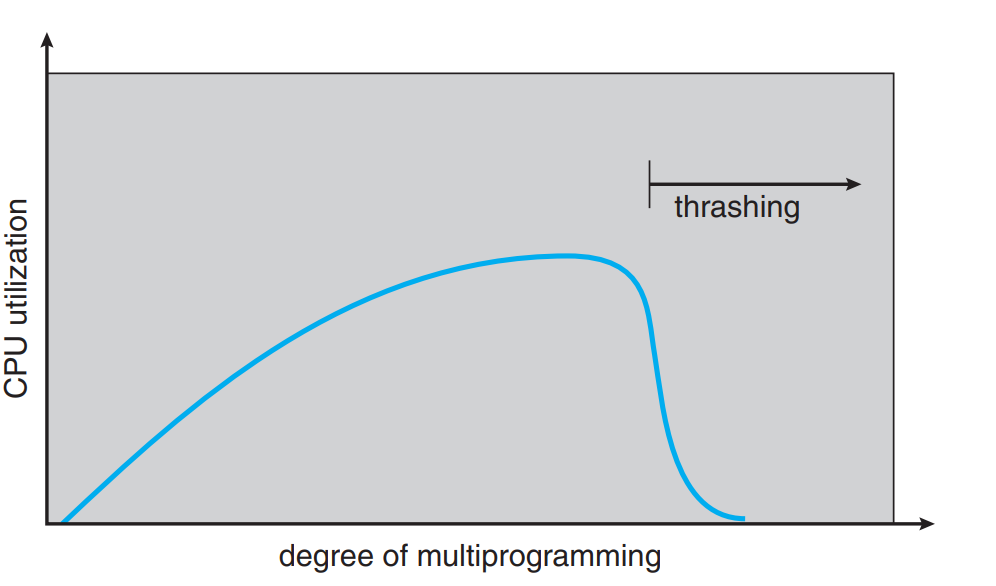
Prevention
- Thrashing can be limited by local replacement algorithm or locality algorithm.
- A locality is a set of pages actively used together. The process is moved from one locality to another
Working-Set Model
The working set comprises of the pages that are most recently actively used. If the total demand of pages inside the working set is more than the total pages available then thrashing occurs/
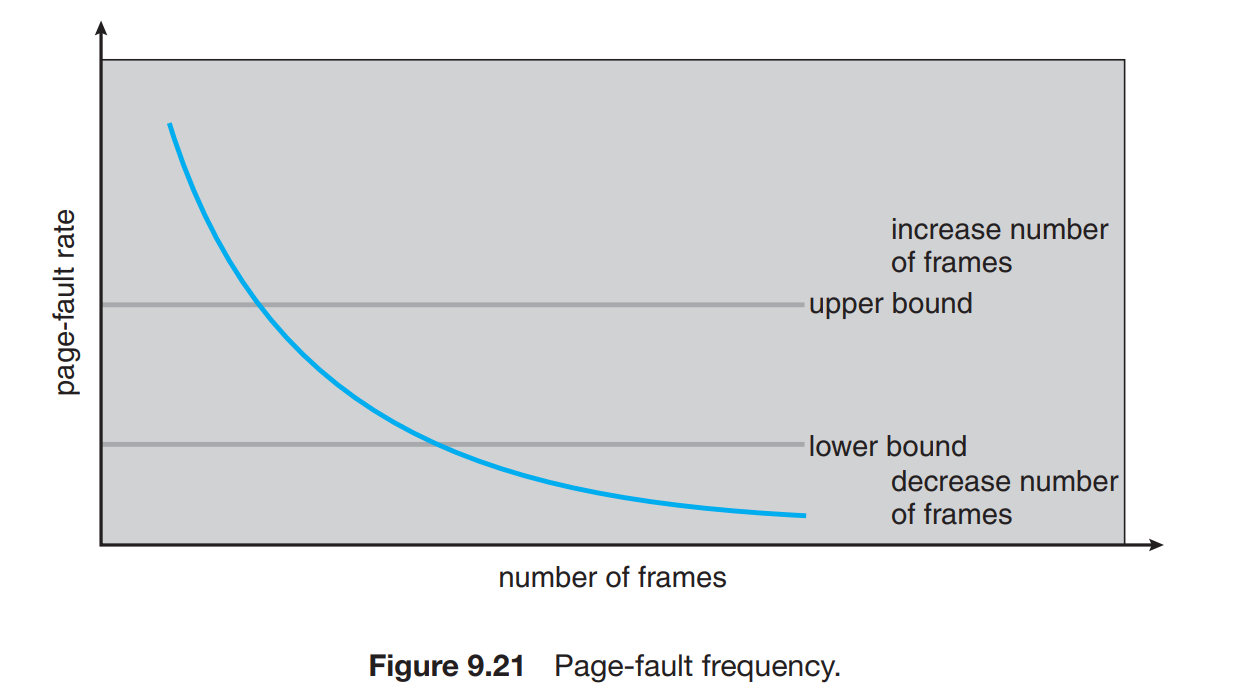
Page Fault Frequency
If the page fault frquency is high then the process needs more frames else the frames available are surplus.
Memory Mapped Files
- We have to map a disk block to a page in memory.
- When the process is going towards a working set then there is a peak of page faults and as the working set is loaded inside the process memory, the page fault frequency again decreases.
- The shared memory points to the shared memory mapped by the processes.
- It is done by using
CreateFilefunction to open the file and thenCreateFileMappingfunction to map the file inside the memory. MapViewOfFilefunction establishes a view of the file inside the virtual memory.- The shared memory is called
SharedObjectthat is to be mapped by both of the processes in their virtual space addresses.MapViewOfFilefunction returns a pointer to this shared memory object.

UnMapViewOfFilefunction removes the mapping of the file.
Memory mapped I/O
- Programmed I/O is the process in which the system checks for the evry next byte to be transferred through the I/O
portin a loop continuously. - While when the system receives an interrupt everytime it has to receive the next byte then the process is called
interrupt drivenmapping.
- Programmed I/O is the process in which the system checks for the evry next byte to be transferred through the I/O
Allocating Kernel Memory
- There are two methods to allocate free page memory to the kernel system:
Buddy system
In this system the segments memory is divided into the powers of 2 such that the memory available for the process is just more than the required memory segments for the process. For ex: A 64-bit segment memory is needed for every 33-bit required process or memory requirement of 33-64 bit.
The drawback is the internal fragmentation as most of the internal segment memory gets wasted.
Slab Allocation
- A slab is a set of one or more physically contiguous pages.
- A cache consists of one or more slabs.
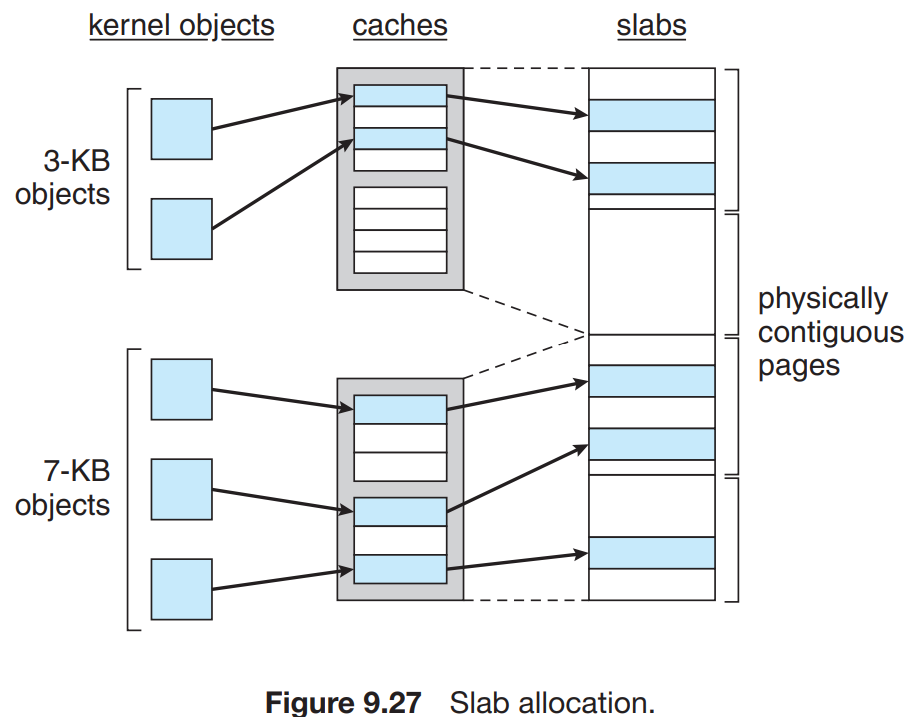
- The kernel objects are assigned to the cache memory that are then assigned to the slab as physically contiguous memory allocations.
- The slab initially has objects marked as
freethat can be used to satisfy the request of the cache memory. - As these objects are used by the system they are marked
used. - If all are marked
usedthen it is calledFull slab, if it has all markedfreethen it is calledEmpty slabor else it is calledPartial slab. - Fragmentation is eliminated as each object has an associated cache memory.
PrePaging
- As the swapped out process is brought back into the memory to be restarted, prepaging is an attempt to reduce this level of initial paging that also occurs during demand paging in its every level.
- This is to bring all the pages required into the memory at once.
- The drawback is that it is not certain that all the prepaged pages will be used and it will be costly for the efficiency of the sysytem.
Page Size
- It generally varies from 2^12 to 2^22 bytes.
- As the page size decreases the page number increases and thus the page table size increases which is undesirable as each process must have its own copy of the page table.
- Thus large page size is desirable for the processes.
- But to reduce internal fragmentation we need smaller page size.
- Internal fragmentation and locality allocation demands for smaller page size while the I/O time and page table size demands for larger page size.
- TLB
- Hit ratio is the percentage of virtual addresses resolved insdie the TLB instead of the page table.
- TLB reach is the amount of memory accessible from the TLB or the number of pages multiplied by the page size inside the TLB.
Inverted Page Tables
- This donot has the virtual address to physical address translation as it stores the pages using
<process-id,page number>. - But as demand paging requires the information about the virtual addresses of the pages, there has to be a separate external page table maintained for this purpose tha tprovides with the address mapping of all the pages.
- As they are only required when the page faults occur, they are not required much generally and thus they are also paged in and out of the memory as per required by the process.
- There is a special case here :
What if the page fault occurs when the scheduler is trying to find the page table inside the backing store , then that leads to multiple page faults. However this occurs in many rare situations but this needs to be handled by the system that causes delay in page lookup process.
- This donot has the virtual address to physical address translation as it stores the pages using
Windows
- The process of clustering is used in which in case of any page fault due to demand paging the pages following the page that is required are also brought into the memory.
- These pages comprise of the working set that has a
working-set maximumand aworking-set minimum. - If the page is not found inside the working set of the process then the page is to be replaced or brought into memory working set.
- Here
LRUis used for page replacement. - If the amount of free memory falls below the working set minimum then the process of
automatic working-set trimmingis executed. This evaluates the number of pages allocated to the active processes and checks if the pages allocated to them exceeds their working-set minimum to replace those pages with the pages that has to be assigned the pages to the current process.
- Solaris
lotsfreeis the parameter to check the paging status. It is equal to the 1/64 of the total physical memory size and thus is the free memory amount goes lesser than this parameter then thepageoutoccurs that
- There are two methods to allocate free page memory to the kernel system:
- When the page fault occurs then the CPU must take the page out from the secondary storage memory to the physical memory frames but if there are no
Storage Management
Mass storage Structure
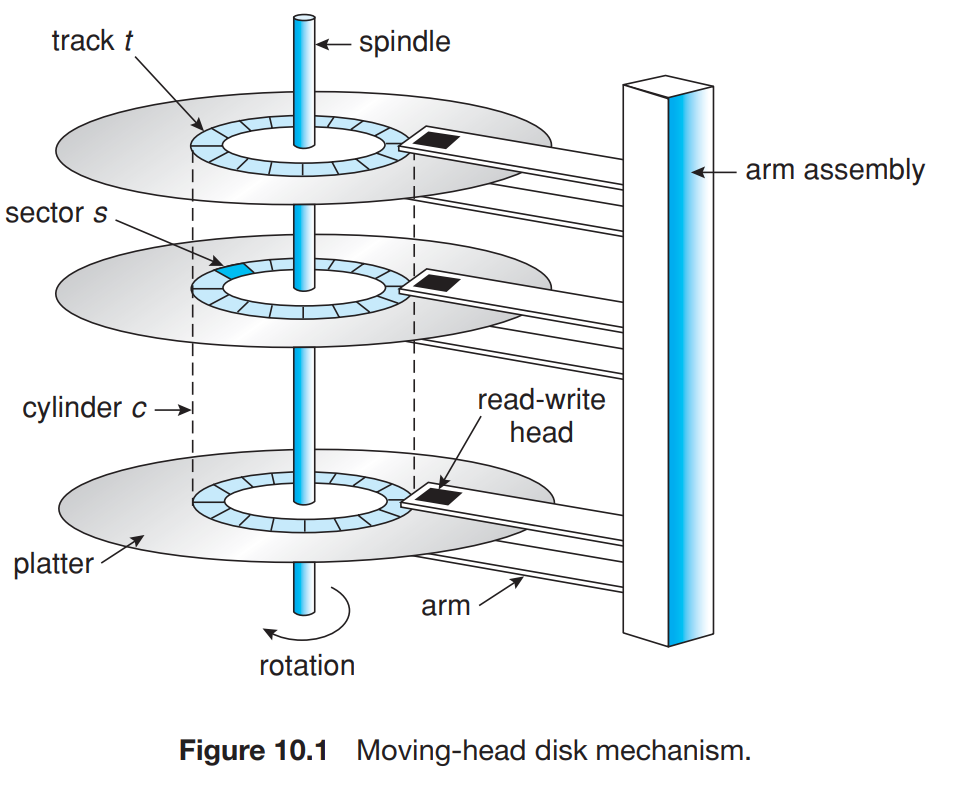
- Magnetic Disks
- Head crash is when the head is contacted with the rotating disk that causes damage to it and cannot be repaired easily.
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
- Transfer rate is the rate at which the data flows between the drive and the computer.
- Seek time is the time to move the disk arm to the desired cylinder.
- Rotational latency is the time taken by the desired sector to get to the head to be read.
- The I/O bus is the set of connecting wires between the disk drive and the system. Some of the buses are: serial ATA (Advanced Technology Attachment), USB (Universal Serial Bus) and Fiber channels.
- The data is transferred inside a bus using controllers. Host controller is at the end of the system. Disk controller provides disk transfer of data.
- Solid State Drives
- They have negligiable seek time and latency.
- Some of them connect directly to the system bus to reduce latency further.
- Magnetic Tapes
They are much slower and thus not much useful.
```
Effective transfer rate is the rate at which the data is read from the disk memory.
Stated transfer rate is the rate at which the data is transferred to the operating system.
Effective rate is always lesser than the stated rate due to latency rates and overheads.
``` - Disk attachment
- This is done by two methods: I/O ports mapping and Network attached storage.
- IDE or ATA is the bus architecture used generally by the computers.
- Network attached storage
This is accesses using RPCs (NFS on UNIX and CFIS on Windows) then the data ia accessed through TCP or UDP.
It provides help to the systems attached to the same LAN or any other type of network but is less efficient.
The drawback is that the communication needs the bandwidth of the network and thus this increases the latency of the system data accessing.
- Storage Area Network
- It is the connection between the servers and the storage units.
- This can dynamically allocate storage to the hosts.
- It also helps the cluster of servers to connect to multiple hosts at the same time to access data.
Disk Schedulling
Disk bandwidth
It is the total number of bytes transferred divided by total time between first request of service and completion of last transfer
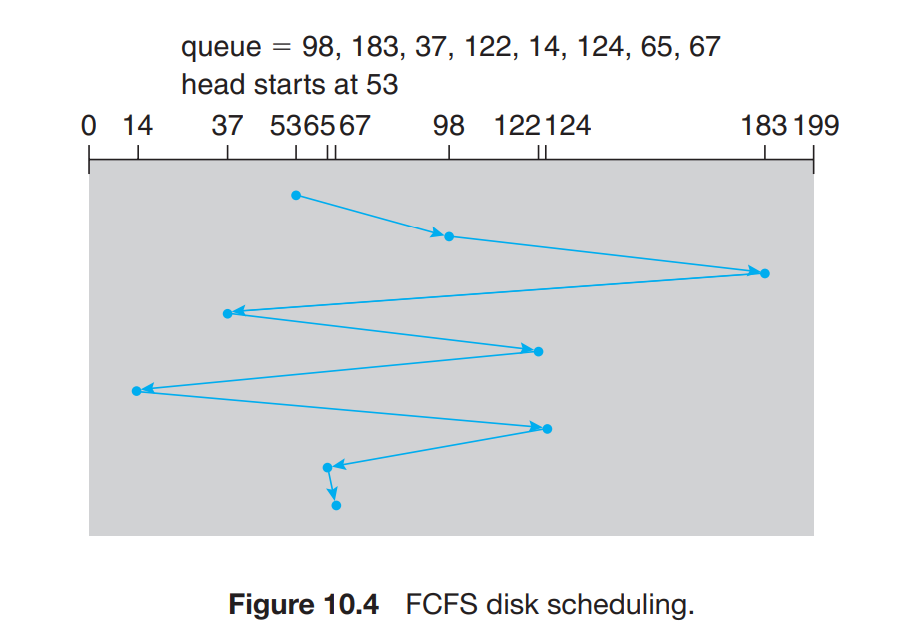
FCFS Algorithm First come First served basis.
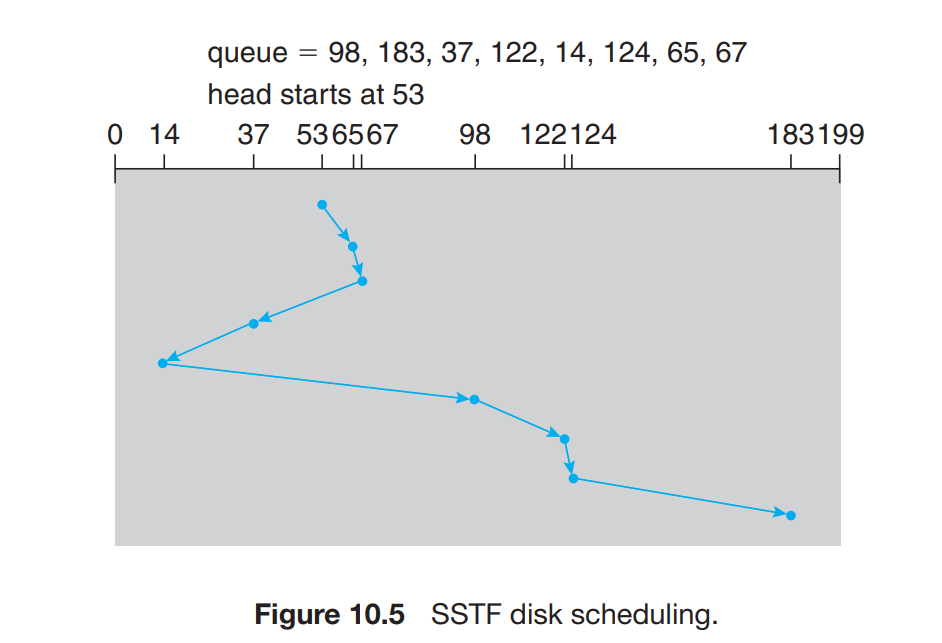
SSTF Scheduling
- Shortest Seek Time First
- The request with the least seek time from the current head position is selected.
- This needs head movement of more number of cylinders than the FCFS algorithm but it improves the efficiency of the system.
- But this can lead to request starvation as the request that is very far away from the head pointer may have come very early inside the queue but it cannot be executed until there is a request with the shorter job than it near the head pointer.
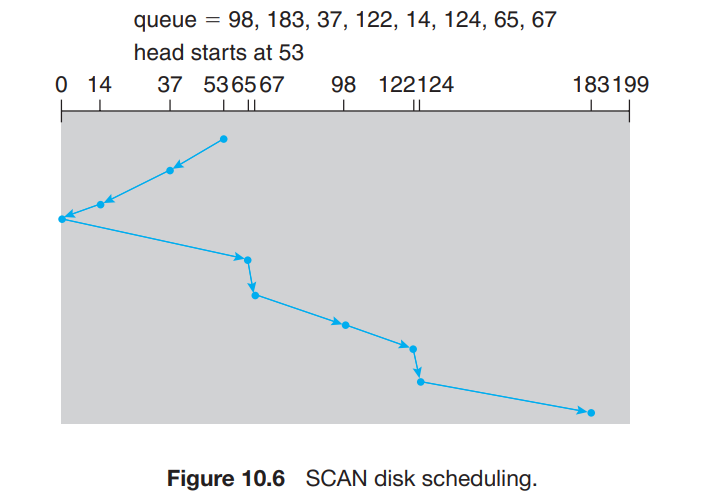
SCAN Scheduling
- As the head reaches the end of the disk while reading it then it reverses its direction and does it back and forth and thus this is called
Elevator Algorithm. - Consider the head is at
53and moving towards the initial position of0. Then it will move towards37and14next and then it will reverse ots direction at0and then access elements65,67,....This decreases the number of cylinders required at a very lower rate.
- As the head reaches the end of the disk while reading it then it reverses its direction and does it back and forth and thus this is called
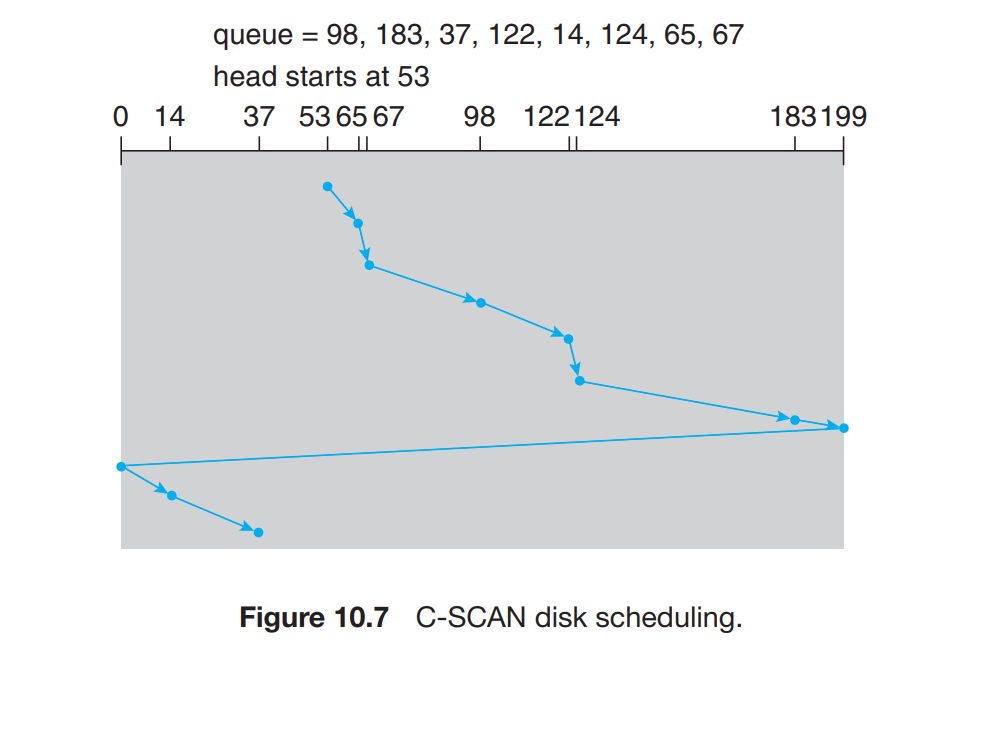
C-Scan scheduling
Circular Scan Scheduling
LOOK Scheduling
In most of the systems C-scan and SCAN algorithms are implemented in a way that the head stops until it finds the last request in a direction and then it reverses its direction.
Disk management
Error correcting code is the bit that is like a stack canary and becomes corrupted as the disk is overwritten and thus the disk has to maintain a copy of that stored inside the backing store.
Boot Block
The
bootstrapprogram is the program that is run at the booting initialization of the operating system and then the RIP jumps to the first instruction inside theROMgenerally to start the Operating System Kernel.ROM needs no initialization and thus is at a fixed location.
The disk that has the boot blocks that has the program of booting sector is called the booting disk.
It cannot be infected with virus as it is read-only.
Master Boot Record is the first code that is placed inside the hard disk.
Bad Blocks
They are the blocks of the hard disk that are malfunctioning or defective or unable to store data efficiently
- They have to be handled manually or with IDE controllers.
The bad blocks are flagged and marked unusable by the controller so that no memory is allocated by the controller at those regions or blocks.
- Sector sparing is to replace these bad blocks with spare blocks or it is called forwarding.

Sector slipping is to slip the blocks by one each so that the bad block data can be mapped to the block next to it.
If
17is bad then slipping makes18->19,201->202,..... This gives space to17to be mapped into18.- Soft error is to tell the controller to not store data at the bad block but data is not usually lost here.
- Hard error is that the data is lost at the bad block and it has to be repaired.
Swap Space use
Overestimation of the required swap space is better than the underestimation as it involves abortion of the program and crashes as there is not enough space in the memory. Linux sets up approximately double of the swaqp space than required to make sure that the memory data is stored inside it.